指令微调(Instruct Fine-tuning)
背景
大模型的对齐阶段,一直都是重点关注的地方。因为随着大模型的工程技术的发展,高效、稳定、持续地训练大模型的门槛已越来越低。预训练对数据的要求相对来说也容易满足,尽可能地千方百计穷尽数量、高质量和多样性。而指令微调(IFT),或者是监督微调(SFT),在数据筛选、构建、获取、优化等方面的工作,决定着对齐人类指令和偏好,愈发显得重要。微调之后的基于人类反馈的强化学习(RLHF),亦是如此。众所周知,chatgpt的类似工作 Instructgpt,就是重点建设这种能力。

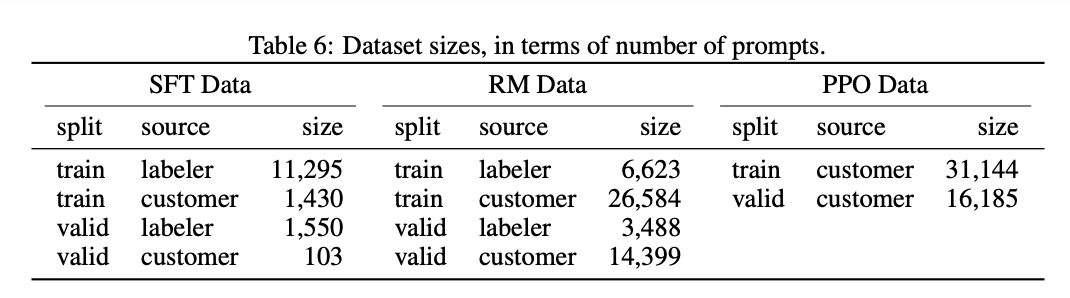
可以看到,openAI因为有大量的线上用户api的数据,他们直接利用此些数据做了监督微调,并且量不是很大。我们没有大量的用户api数据,最开始也不太清楚如何挑选、建设 13000 的 (prompt, response) 对的微调数据。此外,亦有大量的论文、开源工作,如FLAN、OPT等,利用现成的之前开源的NLP数据集进行探索建设,逐渐沉淀完善自己的指令微调(IFT),监督微调(SFT)等工作。
总体目标
大模型的监督微调阶段(SFT),主要是对齐人类指令和偏好,以便为用户尽可能提供准确、有用、无害的回复。聚焦“指令”这一部分,重点进行建设,亦称“指令微调(IFT)”。通过构造一部分 (prompt, response) pair对的微调数据,能够让模型更好地遵循指令。
切入点
大量的 IFT 工作,以传统NLP任务和开源NLP数据集为着手点,进行能力建设。利用 prompt template (BigScience的prompt-source工作)技巧,将传统的NLP数据构建出大量的 (prompt, response) pair对的数据集合,如 xp3、Flan-v2 等等。
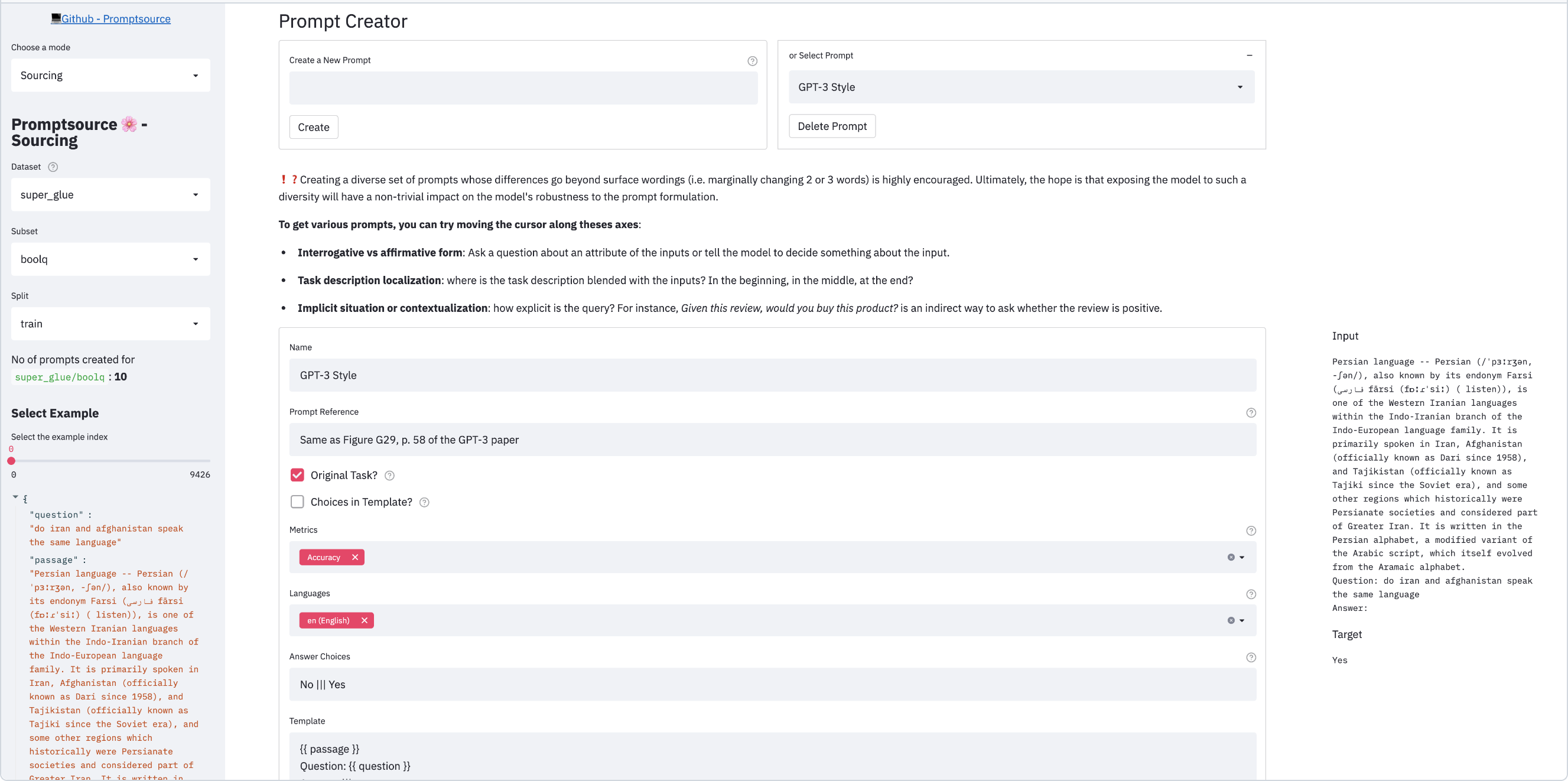
希望先在传统的 NLP 任务上,探寻建设大模型对指令遵循能力的规律,后续再进行深入和优化。
NLP-IFT任务
任务设置
| 任务类型 | 指令类型 |
|---|---|
| 文本分类 | 主题分类、情感分类、意图分类、文本蕴含 |
| 文本匹配 | 短文本相似度匹配、QA匹配、query-doc匹配、标题-摘要匹配、短文-关键字匹配 |
| 信息抽取 | 实体抽取、SPO关系抽取、事件抽取 |
| 材料总结 | 总结标题、总结摘要 |
| 材料阅读理解 | 选择题、判断题、因果关系分析、完形填空、简答题 |
探寻目标
预训练模型(基于Llama2-70b基座,经过1T中文Token持续预训练产出)
- 英文NLP任务的IFT数据对中文 NLP IFT任务的影响(跨语言迁移能力)
- 在NLP 任务上,分别探索 held in&held out 对于建设遵循指令能力的数据要求
- 在NLP 任务上,分别探索 held in&held out 对于建设遵循指令能力并对标传统小模型(sota)性能的数据要求
训练&评估&结论
按照任务设置,逐条构建 1900 左右高质量精标数据作为训练集,同时进一步建设高质、多样、有代表性的 100 条作为评估集,采用 GPT-4 的自动评估。
- 英文NLP-IFT任务数据能够有效地帮助中文NLP-IFT任务提高指令遵循能力,即使加入英文IFT的数据是中文IFT数据的4倍之多,都不会使模型在中文NLP任务遵循能力上有退化。即在NLP-IFT任务遵循指令能力上,模型呈现强烈的跨语言迁移能力。
- 对于 held in 的NLP任务,当每个任务(任务设置表格)在3条以上数据,整体数据量在70条左右,即可保证指令遵循
- 对于 held out 的NLP任务,当总体样本数量达到 1000 左右,且每个任务接近均匀分布(即多样性有一定保障),模型呈现出遵循指令能力的泛化,即有了 held out 能力
- 对于 held in 的NLP任务,对于某个任务数量在50条以上数据时,模型能在此任务上基本可以接近传统小模型的sota性能的90%左右
- 当中文NLP任务数据数量 : 英文NLP任务数据数量 = 1 : 0.7 时,实验中此配比达到了最优中文NLP任务的性能。
IFT深入优化
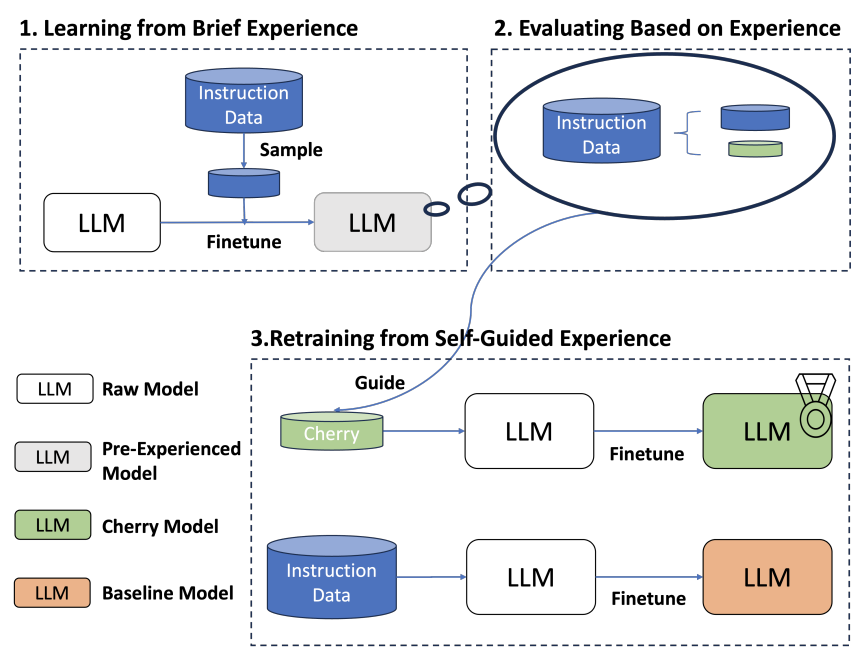
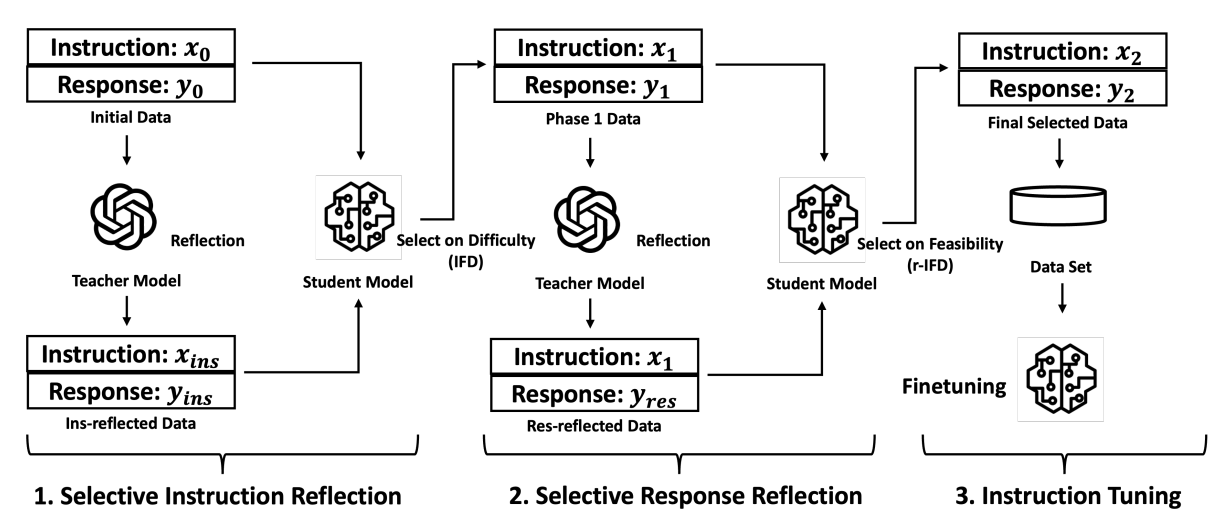
当拿到上述结论后,我们对大模型的指令遵循能力基本有一定的感知能力。此后,我们通过 self-instruct,或者 Evol-Instruct 思路,构建更高质量、更高多样性、适当复杂性、更多开放性的数据,来不断提高我们模型的指令遵循能力,即不断使大模型对齐人类指令。此外在深入优化建设IFT数据,可以考虑各类开源指标指导,比如IFD指标等,甚至可以采用主动学习进行挑选。
- 更高质量:大模型对于训练数据的质量要求特别高,哪怕只是一条不好的训练数据,都相当有可能造成恶劣badcase
- 更高多样性:大模型不仅是指令泛化能力,都是对数据的多样性、丰富性提出很大的要求,多样性不足,大模型特别容易过拟合某种范式,导致不限于生成重复token的复读机严重badcase
- 适当的复杂性:大模型对于数据的要求,不能太过简单,导致各项能力不足;但也不能过于难,甚至超过预训练的知识,会导致幻觉
- 更多开放性:与多样性类似,场景、领域开发。
指令遵循评估
指令遵循能力是一种不像传统模型评估容易,严重依赖人工评估会导致低效,依赖 GPT-4 评估,会导致引入 GPT-4 的偏置,并且 GPT-4 评估不总是相当置信。对于重要的体现指令遵循能力的点可能关注不够,而对于一些细枝末节又过于吹毛求疵。可以在 prompt 工程上进行优化,比如考虑引入“评估要点”,或者“正反示例”等。甚至可以引入模型评估,比如 reward model,积累下的评估pair对,甚至可以辅助后续 RLHF 阶段的数据迭代。