监督微调(SFT) --翻译场景
七月 01, 2023
背景
监督微调(supervised fine-tuning),是重要的对齐人类指令和偏好的阶段。它对数据的质量、多样性、丰富性等都有很大的要求。而且也是与构建大模型最终目的息息相关的。不管是通用智能大模型,如类chatgpt产品,还是垂域大模型,如各种垂直域结合RAG的大模型,SFT数据的建设都是非常重要的。围绕着 SFT 的模型和数据建设,有很多论文、工程等开源工作。其中,作为最基础的一项场景,翻译,此场景既是典型的 SFT 应用场景之一,也是考验模型跨语言能力迁移的重点方向,更是基于原生英文 Llama2 基座的中文大模型本土化关键点,着重需要重点探索、建设、优化。
目标
- 中英&英中翻译场景,能够作为SFT数据中的一小部分,辅助支持建设通用SFT数据的高质量、多样性等,SFT除翻译外,还包括的其余重点场景有:通用文创、通用问答、通用逻辑(数理/推理)、教育(各类K12考试/公务员/法律题目)、代码、指令IFT等;
- 中英&英中翻译场景,能够通过Chat模式,能为用户提供远超传统机器翻译产品的用户体验;
- 在字词、句子、段落、篇章等各个粒度,对政经、教育、商务、旅游、科技、医疗、文学等多个领域提供优质的翻译服务。
定位
中英&英中翻译应该具有两个定位:
- 能够作为SFT数据中的一小部分,数据量在百、千量级,高质量、多样性,辅助SFT数据、模型建设;
- 较大量级,如万量级,能够在预训练模型(基于Llama2-70b基座经过1T中文Token持续预训练产出)基础上单独进行SFT,产出翻译场景的垂直领域模型,产品应用级可用。
中英&英中翻译数据建设
数据源
1. 可可英语
2. 各类论文智库中的中英对照摘要

3. 各类官方、商务等翻译社
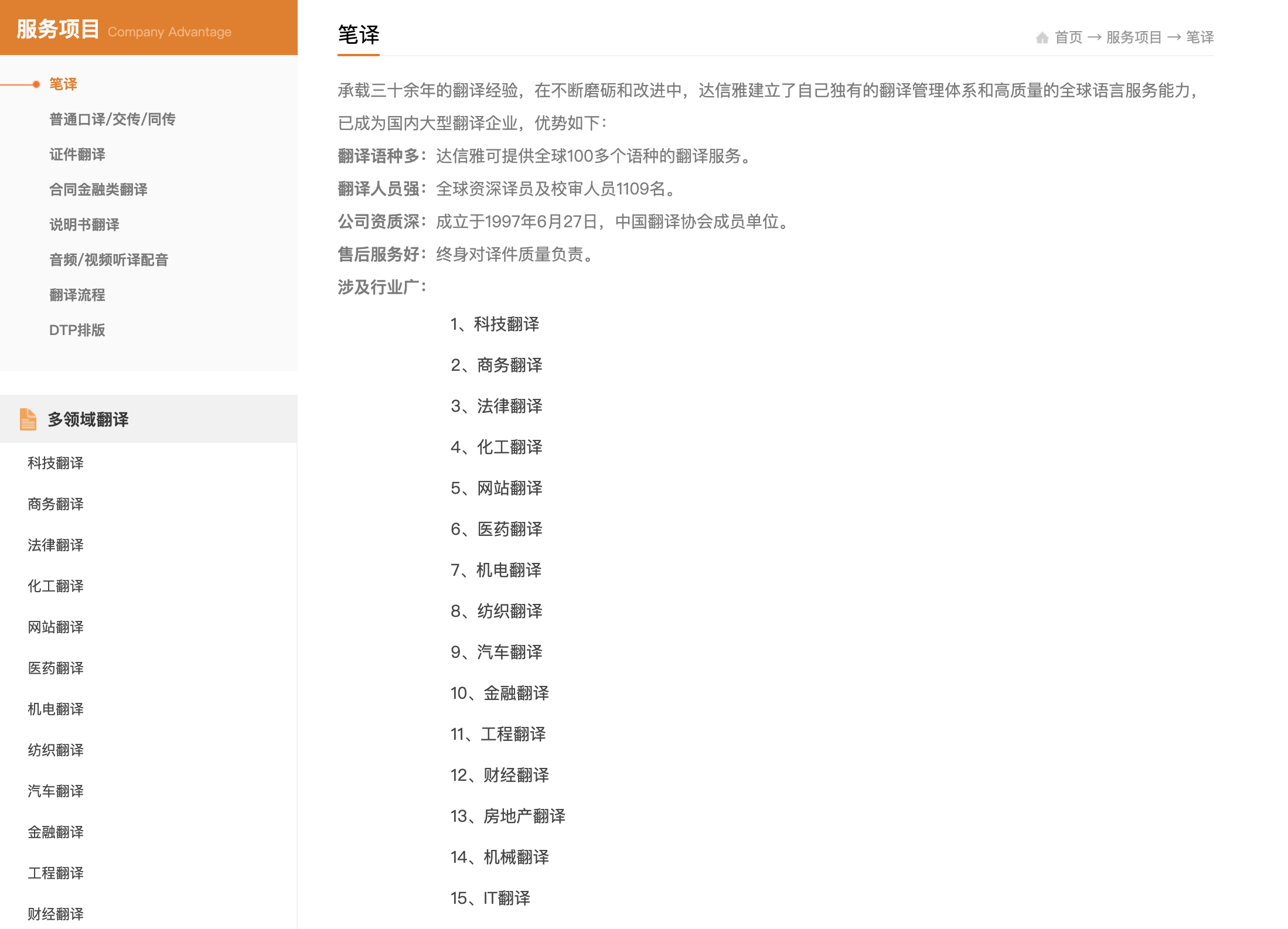
4. 各类开源的中英翻译数据集
Casia2015、casict2011、neu2017 等传统的中英对齐翻译数据集,质量都较差,大约在 90% 的精度,并且中文的翻译腔非常严重,完全达不到翻译的“信、达、雅”的要求,并且领域特别单调,新闻居多,刻意找寻,医疗和演讲倒也有一些。可以作为进一步人为修改或者采用GPT-4等自动方法,作为候选补充等。
数据体系梳理
1 | 一:领域 |
中英&英中翻译Prompt建设
搜寻网上所有中英&英中翻译的与chatgpt交互示例

利用 GPT4 进行中英/英中翻译prompt生成
直接生成具体数据无关的prompt
1 | prompt = '''给出一些中英翻译任务最好用的中文prompt,能够让chatgpt更好地执行翻译任务''' |
将整段的对齐中英语料借助 GPT4 拆分更细对齐粒度
1 | prompt = '''根据给出的双语文本,生成一些词句粒度对齐的中英互翻的中文指令,并给出回答: |
中英&英中翻译评估体系
自动评估
BLEU-RT:Learning Robust Metrics for Text Generation
人工评估
评测原则
- 翻译领域通用的标准原则——信达雅
- 信
- 译文与原文在含义上属于对等关系,不得出现漏译、多译,造成原文与译文信息不对称,或是误译造成译文偏离原文意义
- 达
- 格式规范:无拼写、标点符号等客观错误;专有名词、专业术语等必须符合规范
- 语言规范:用词恰当、语法正确、语句通顺、不得出现逻辑不通、语句不连贯或出现翻译腔
- 译文中要适当反映原文的特殊句式效果,如强调句、同位语从句等
- 雅
- 关于“雅”的要求,主要针对文学相关场景,要求译文在通顺的基础上能够使用高级丰富的词汇、句法结构或翻译方法(意译),使得其表现手法或写作风格与原文贴近
- 信
- 场景角度的专业性、权威性
- 商务英语
- 商务信函,涉及具体商务操作,要求准确把握原文信息,并且应尽量避免使用模棱两可的语言使句意不清而产生误解和歧义
- 涉及货物价格、重量、日期等有关数字的翻译必须准确严谨具体
- 用词严谨专业,符合商务英语的套路和习惯表达,主要体现在大量的专业术语、行话、缩略语等
- 商务信函符合格式规范,日期、地址等符合中英文各自表达习惯
- 符合商务沟通语境
- 商务信函,考虑中英文各自信函的文本格式,翻译时采用对应风格
- 商务会话,尤其注重会话礼仪、人物称谓、表达方式等,传达“礼貌”、“尊重”的意味
- 教育
- 文学作品、名人名言翻译,尽量采用意译手法保持原文立意和风格
- 医疗健康
- 医疗领域的许多词汇比较生僻,但有固定中英文表达方法,例如疾病、科室、药物、治疗手段、症状等,翻译时必须使用其专业术语
- 政经
- 政治、经贸类的专业词汇、短语、需要准确翻译,尤其是官方语言
- 政经类公文,如政府工作报告,需要体现公文写作逻辑严谨、语体规范的特点
- 旅游
- 旅游业相关专业词汇的翻译要符合标准
- 实际旅游场景中,在翻译时应该采用以游客为中心的翻译策略,在选词上要尽量避免过于专业和生僻的词汇,在语言结构上要尽量简短易懂
- 注意风格的切换,迎合读者的思维模式以及文化的审美诉求,灵活处理文化和美学的信息
- 商务英语
评估细则
- 6个打分维度,打0,1,2分(准确性、全面性、表达性、结构性、相关性、无害性)
- 4档,1,2,3,4
- GSB评估
模型性能
我们模型:预训练70b模型 + 500 条精标小样本(计划加入SFT通用数据)
自动指标 BLEU-RT
| 场景 | 我们模型 | GPT3.5 | 百度翻译 |
|---|---|---|---|
| 中翻英 | 0.6990 | 0.7129 | 0.7006 |
| 单元格 | 0.6872 | 0.6925 | 0.7351 |
人工评测
选用第三方的三家评测机构,针对百度翻译、gpt3.5、文心一言旧版、Ours(预训练70b模型 + 500 条精标小样本)、文心一言4.0,最终的评测结果如下:
第一名:百度翻译
第二名:gpt3.5
第三名:文心一言4.0
第四名:Ours(预训练70b模型 + 只加 500 条翻译的精标小样本)
第五名:文心一言4.0
考虑到我们只有 500 条精标小样本达到的水准,基本可以确定,此方案,在万量级左右的翻译效果,基本能够达到产品级应用
体感(show case)
散文翻译 show case

后期优化
- 我们可以考虑加入相关的翻译技巧类数据,或者高质的中英平行语料进行持续预训练;
- 按照数据体系,对中英翻译样本进行放量,基本可以预见,在万量级别下,可以达到产品级别应用,且用户体验很惊艳。
查看评论