LLM 个人思考沉淀
LLM 与 Diffusion Model 应该是当前 AIGC 领域大火的几个方向。其中大语言模型 (LLM) ,参与程度较深,有一些个人的思考沉淀,记录下来,以便更好地进步。
LLM 本质
LLM 由 openAI 的 chatGPT 引爆,chatGPT 与 openAI 的 InstructGPT 基本一致 (仅在喂入的数据建设上略有不同),使用放大到千亿参数规模的自回归语言模型 GPT-3 作为基座,经过监督微调 (SFT) ,再经过人类反馈的强化学习 (RLHF) 的多次迭代,最终相较于之前,达到一个质的飞越 (与传统 NLP 模型相比,跨物种级别的飞越)。
从 chatGPT 入手,理解 LLM 本质:
- 预训练阶段,即通过“预测下一个Token”的自回归模式,在大量语料上进行训练,从而得到基座模型,如 GPT-3 等,是作为知识(智能)的摄入阶段。
- 指令微调阶段 (instruction tuning,instruction fine-tuning,IFT) 或者是监督微调阶段 (supervised fine-tuning,SFT),更多是对齐人类的指令,激发预训练摄入的知识。
- 这一点与传统 NLP 模型微调有较大区别,之前 fine-tuning 传统的 NLP 模型,的确希望模型能在预训练之后的基础上再学习新的监督任务,尽管可能损害之前预训练学到的其他知识泛化性,也是可以容忍的,只要能够很好地解决好新的监督任务。
- 而 LLM 视角,IFT 和 SFT 只是希望能够激发预训练摄入的知识,让模型能对齐到人类的指令。比如是“写一篇文章”还是“翻译一篇短文”等,至于完成这些具体任务所需的能力,是依赖预训练阶段摄取的知识,IFT或者SFT阶段只是利用这些指令,教会模型进行激发。
- 人类反馈的强化学习阶段 (RLHF),主要是为了对齐人类理想的、高质量的响应标准,包括提高生成内容的质量、尽可能保证信息准确,降低幻觉(一本正经地胡说八道),去毒。
- 因为在预训练阶段摄入大量的知识,经过 IFT 或者 SFT 阶段的激发,模型虽然能够响应人类指令,但响应的内容存在很多问题,包括不限于生成质量、信息准确性,甚至包含一些偏见、毒性内容等。
- 这些偏见,毒性内容,是由预训练数据的模式缺陷导致的,比如包含了更多的有偏见的社区回答数据等。
- 通过人类反馈的强化学习阶段,模型能够更清楚地学习到,什么样的回答是符合人类期望,价值观的。
从数学概率论/信息论入手,理解 LLM 本质:
- LLM 本质上,依然是“预测下一个Token”的自回归模式,即文字接龙游戏,数学上,还是学习文本模型的一些统计概率特征,还是通过解码出下文正确的文本,利用概率分布,构建出 loss ,进行梯度反向传播优化。从这个角度来看,与传统的 NLP 模型无异。
- 既然与传统的 NLP 模型无异,至少在数学本质上无异,为什么会有质的飞越?如果有对传统 NLP 模型(十亿参数规模以下)训练的经验,设计多个 epoch 进行训练,loss 的下降在 epoch 间是较为平滑的;但是当模型参数达到十亿,甚至百亿、千亿规模,会发现,loss 的下降随着 epoch 呈现明显阶梯性。
- LLM 的训练 loss 随着 epoch 呈现明显阶梯性下降趋势,说明它的参数量大,模型拟合能力太强(可以简单理解为模型记忆预训练数据模式的能力),这也是预训练 LLM 一般只设置一个 epoch 的原因。强大的记忆数据模式的能力使 LLM 在知识记忆上,远超传统 NLP 模型,当预训练数据大到囊括人类所有的文本信息时,传统的 NLP 模型容量不够,记不住甚至混淆,而 LLM 有较少此问题。于是看起来 LLM 在多个领域上,有很强大的、通用的解决问题的能力,实现所谓“质”的飞越。
- LLM 的涌现现象,尤其通过思维链(CoT)加持,貌似说明 LLM 除了拟合能力(记忆预训练数据模式的能力)之外,还有传统 NLP 模型难以望其项背的推理能力。
- CoT 的 prompt 构建,也是尽可能遵循 step by step 的模式,更符合文字接龙游戏规则,属于人类主动对齐 LLM 模式。
- 据最新相关论文,所谓的涌现,只是指标度量的问题,很难通过现有的一些指标,如准确率、EM、ROUGE等很好地、循序渐进地度量出 LLM 在解决推理等任务上的性能变化,往往呈现出跳跃现象,即所谓的涌现能力。当然,此一问题还待进一步研究。
- 从信息论角度,openAI 的观点“信息压缩即为智能”。
- 巨量的参数支撑着强大的记忆预训练数据模式的能力,如果这个能力趋向于无穷大,LLM 就可以看作是将所有信息进行无损压缩的一个容器。当进行响应时,对应着输入的数据模式,检索输出的数据模式。而这是参数量小的传统 NLP 模型所不可比的。
- 曾有一篇 S4 模型的论文,量化了模型在训练阶段的压缩数据和记忆存储的问题,文章中,通过涉及到一阶微分方程的数学理论体系,实现了较大程度的压缩数据能力,从而在超长文本(序列长度上万)的建模任务上,达到远超传统的 transformer 的性能。
LLM 复刻
自从 chatGPT 爆火之后,LLM 领域的研究论文、工程、开源模型等喷涌而出,社区甚至夸张到以小时为单位计的更新迭代速度。结合上述对 LLM 本质的分析,会发现,相较于之前传统 NLP 模型,无非是靠更大的算力和更多更优的数据训练加持,来实现 LLM。汗牛充栋的资源和各方工作进展不在此赘述,仅从复刻 LLM 的方法论和一些具体细节,记录自己的思考和沉淀。
- 评估体系优先明确并建立,LLM 的训练成本极大,复刻 LLM ,主要是复刻其解决任务的能力,或者对标达到某个既定水准。因此要有明确的评估标准和体系,以便进行参考指导。包括模型参数规模、数据规模、算力预估、模型结构选型、数据配比、迭代方向等,都需要根据评估体系进行设计和引导。保障复刻 LLM ,尽可能少走弯路,用最高的性价比达到既定的目标。
- 评估体系要对标现有开源的指标体系,有很多 LLM 的评测工作可以参考。要保证评估体系能尽可能客观、公正地反映出 LLM 实际能力水位。实操中,往往由于评估集的选择(语种、任务类型等)、评估指标的选用(拼接选项利用 ppl 计算准确率 VS 直接采用生成解码文本完全匹配计算准确率)、评估方式的选用(zero-shot、few-shot)等,会有较大不同。因此需要确保一致,至少保证几个重点关注的任务领域,业界公认的 LLM 榜单,能够在自建的评估体系得到印证。
- 当然,也可以只用业界开源的 LLM 榜单,但刷榜式的复刻 LLM ,还是少数,更多的 LLM 复刻工作,主要是赋能自有业务,因此,在确保评估体系印证 LLM 榜单的前提下,会补充自有业务进入评估体系。
- 评估体系建立后,不论是进行模型选型,还是数据配比等,要遵循 Scaling law 并验证是否符合趋势。即先从几B、十几B、再几十B,上百B的参数规模上扩大(1B==10亿,GPT-3为175B,千亿规模)。
- openAI 有对应的 Scaling law 研究,即模型参数、算力资源、数据量、loss 收敛效果的权衡,确保 LLM 在训练期间,符合这一趋势,尤其是 loss 收敛的趋势,确保最终复刻 LLM 的有效性。
- LLM 的训练稳定性、loss是否收敛、模型架构是否需要调优、数据质量是否需要提高、数据配比是否需要调整,在参数规模量级不同的情况下,有很大差别,从小到大放缩参数规模,便于尽可能前期暴露并解决各种可能出现的问题,防止高成本的、在大规模参数模型上训练失败的次数,降低风险。
- 预训练
- 数据集构建
- 很多开源的复刻工作可以参考,包括不限于 Bloom、LLaMA、GLM130b 等,都有关于数据集的选用、清洗、去重等建设工作可以参考。实际上,复刻 LLM 最核心的也确实是数据集的构建。正如上文所述,预训练阶段是 LLM 知识摄入阶段,后续各种问题也都是预训练数据的模式缺陷导致。所以预训练数据集构建是重中之重。
- 在预训练数据集构建中,百科知识是比较重要的一部分,此外还有一些网页数据、书籍数据等,只训练一个 epoch ,一般是根据 scaling law 定下数据量,再考虑采样、配比、去噪的工作,其中去重工作比较重要,如文档重复、n-gram 重复等。这是考验复刻 LLM 团队的核心竞争力的工作,就是考验团队积累的数据资源、数据敏感性如何。
- Tokenizer选用
- 不同的 tokenizer ,同样的数据,切分出来的 token 是不同的。而 Tokenizer 的选用,除了一些开源工作指导,比如繁殖率等,更大程度上和所构建的数据集有很大关系。一个好的适配的 tokenizer ,能够让语料更有效的被 LLM 学习到。相反,一个不适配的 tokenizer ,影响着高频 token 和 低频 token 的分布,甚至导致 LLM 的 loss 不收敛。
- 实操中,不可避免地会根据数据集调整字表,重建自己的 Tokenizer ,这个工作需要做很多验证,至少开源的 tokenizer 的效果对比,预训练数据集的 Token 分布情况必不可少。
- LLM 训练成本很高,一般都会有 Packing 策略,即把多条样本尽量拼接为最大序列长度,尽可能避免padding,浪费算力,这就需要在注意头上防止交叉污染,而 Packing 策略是以 Token 为对象的,因此实操中,Tokenizer 的设计,不可避免地要考虑到 Packing 策略。
- 持续预训练
- 一般除了基础研究部门会从零到一进行 LLM 的预训练之外,更多的复刻 LLM 的工作,多是选用开源的预训练模型基座,然后接上自建数据集上进行持续预训练。
- 在实操中,Nvidia的 megatron 3D并行(data、pipeline、tensor),deepspeed Zero-X 优化,还有 DeepSpeed-Chat 的开源
- 不管是从零到一预训练,还是持续预训练,整个过程中,几乎确定可以遇到,随着训练的进行,出现 loss 尖刺,甚至不收敛,甚至发散的状态,有很多开源论文工作有研究,也有解决办法,比如恢复到之前的 checkpoint,丢弃附近的 batch 数据,记录并恢复当前的优化器状态等,可能涉及到的要素有:
- tokenizer 的不适配数据集,当模型在趋向收敛状态时,频繁遇到低频 Token ,导致 loss 抖动,且累计达到一定程度,导致 loss 不收敛。
- Normalization 层放置在注意层前后的结构设计,GLM130b 有对应的研究。
- 精度问题导致,bfloat 精度数据能够节省很大的显存开销,但当 loss 较小时,它的小数位不足以支撑表示,计算向上取,导致 loss 看起来不收敛。
- 数据集中含较多杂质,而这种杂质经过 tokenizer 处理,呈现出来的大多是低频 Token,导致计算此 token 的 PPL 陡然增大,频繁发生导致累积。
- 诸如种种……
- 持续预训练工作,往往是希望基座模型更加适配最终的能力,因此,要确保持续预训练能够比基座模型在上述的评估体系中,拿到更高的基线指标。在评估预训练模型,评估手段多采用 few-shot,针对分类任务,拼接选项利用 ppl 统计准确率。
- 数据集构建
- 指令微调(IFT)和监督微调(SFT)
- 关于 IFT 和 SFT ,业界有不同的观点,openAI 的 chatGPT 就没有所谓 IFT 这个环节,他们利用累积的用户数据、以及专业标注人员等构建的
,即 SFT 数据。而诸如 google 、Meta 以及 bigscience 等机构,他们有些工作,如 FLAN、PromptSource、OPT-IML、T0、Bloomz等,收集了很多之前传统的 NLP 任务数据集,比如文本分类、文本蕴含、摘要等数据集,通过编写 prompt template,转变成 (prompt,respose)格式,这个过程是叫做 IFT,即更明显的解决 NLP 任务的指令数据微调。 - 更有名气的 Meta 开源的 Alpaca,利用 LLaMA 基座,通过 self-instrct 构建 (prompt,respose),效果也颇为震撼。这一个成果,仿佛让区分 IFT 和 SFT 显的意义不大。因为本质上就是上文所述,就是对齐人类的指令,激发预训练摄入的知识。
- IFT
- IFT 工作价值颇受争议,但不管怎么说,它有几个优势:
- 一是可以缓解不少标注数据压力,毕竟如果没有类似 openAI 用户请求数据的资源,全靠人力标注各个领域、各个场景、丰繁指令的高质量 (prompt,respose),成本蛮高;
- 二是相对于 self-instrct 数据质量,之前传统的 NLP 任务的数据集质量更高些,只需借助少部分人力,构建些 prompt 模板,将数据集转换为 (prompt,respose) 格式就可利用;
- 三是“对齐人类的指令从而激发预训练摄入的知识”这一个目标偏大,可以拆分一下,IFT 作为前置,解决些简单的 NLP 任务,为进一步 SFT 提供一个及格的基线。而 SFT 只需要在基线上相应建设。
- IFT 工作价值颇受争议,但不管怎么说,它有几个优势:
- SFT
- SFT 工作重心主要在数据构建上,如果能确保预训练阶段的稳定性,SFT在模型训练上不会有太大问题,无非是解码策略的调优,如 beam search 还是 do sample 之类。
- SFT 的数据构建,各个领域、各个场景、丰繁指令的高质量 (prompt,respose),重在丰富性、多样性;而总的量不会很多,因为 SFT 阶段是为了“对齐人类的指令从而激发预训练摄入的知识”,并不是让 LLM 学什么新的知识。
- 实际上,SFT构建的 (prompt,respose) 最好是 LLM 在预训练阶段习得的,高置信度的数据,更加激发知识,产生出好的respose。尽量保证不含或者少含 LLM 预训练能力之外的数据,因为这些数据会鼓励模型去猜,猜就会增加不稳定,产生所谓的幻觉问题。
- 不管是 IFT,还是 SFT,构建 (prompt,respose),内容丰富,高质量,多样性高,量上面要求并不多。为了降低 LLM 对齐成本,建议构建风格一致的 response,例如“总-分-总”结构,只是风格一致,风格不是格式,更不是内容,只是一种组织逻辑。
- 此外,不管 IFT,还是 SFT之后,相较于预训练之后的模型,生成能力都会受损,被称为“对齐税”,也有较多研究工作,可以参考,用来缓解此问题。
- 关于 IFT 和 SFT ,业界有不同的观点,openAI 的 chatGPT 就没有所谓 IFT 这个环节,他们利用累积的用户数据、以及专业标注人员等构建的
- 人类反馈的强化学习阶段 (RLHF)
- 相关的 RLHF 工作,openAI 有针对 Reddit Summary 工作做过研究,可参考对应论文,且 openAI 在其 github 上开源出很多强化学习套件,比如 PPO 等实现,此外 RLHF 的开源框架也不少,如 safe-rlhf 等,基本开箱即用。
- RLHF,希望模型能够更清楚地学习到,什么样的回答是符合人类期望,价值观的,主要是为了对齐人类理想的、高质量的响应标准,包括提高生成内容的质量、尽可能保证信息准确,降低幻觉(一本正经地胡说八道),去毒。所以让 LLM 能看到它自己之前的输出,通过强化学习迭代,能够得到较大提升。
- 最近,针对强化学习训练不稳定,不收敛的情形,有研究直接采用明确的对齐策略,利用 LLM 自己前后多个输出,构建 pair-wise ,进行迭代训练,效果不逊于 RLHF 。
LLM 进化
AI 智能体
尝试利用 LLM 驱动 ,整合一下其他技术,让模型能够进行反馈,作出策略和动作,形成智能体。
Auto-GPT,是一个能自主迭代、自主迭代(长时记忆)、自我提示且联网查询的新的 GPT 框架,不需要与 ChatGPT 在多轮对话中让 ChatGPT 逐步完成任务,而是最少只需要在第一轮对话中输入需求,Auto-GPT 就能自己分解任务去完成,后期 Auto-GPT 应该能调用更多的工具和插件,甚至是桌面应用。
在《我的世界》,AI 智能体像人一样生存、探索、创作,通关整个游戏。
LLM 的知识编辑
- 探究 LLM 中知识的存储、编辑更新等,有大量相关的研究论文。
显存利用优化&推理性能优化
- 目前采用更为激进的优化技术,可以内存换显存,GLM130b中,可以将千亿模型量化 4 位放在几张消费级的显卡上。
行业 LLM
业务输出
langchain,是一个强大的框架,旨在帮助开发人员使用语言模型构建端到端的应用程序。它提供了一套工具、组件和接口,可简化创建由大型语言模型 (LLM) 和聊天模型提供支持的应用程序的过程。LangChain 可以轻松管理与语言模型的交互,将多个组件链接在一起,并集成额外的资源,例如 API 和数据库。
LoRA: Low-Rank Adaptation of Large Language Models
- 文生图领域,实现了不修改 stable diffusion 模型的前提下,利用少量数据训练出一种画风/IP/人物,实现定制化需求,所需的训练资源比训练SD模要小很多,非常适合社区使用者和个人开发者。同样可应用于 LLM 中,进行业务适配和输出
产业结合
LLM 结合外挂知识库/知识图谱,实现知识更新,满足实效性;实现证据查询,进一步确保 LLM 输出的准确性。
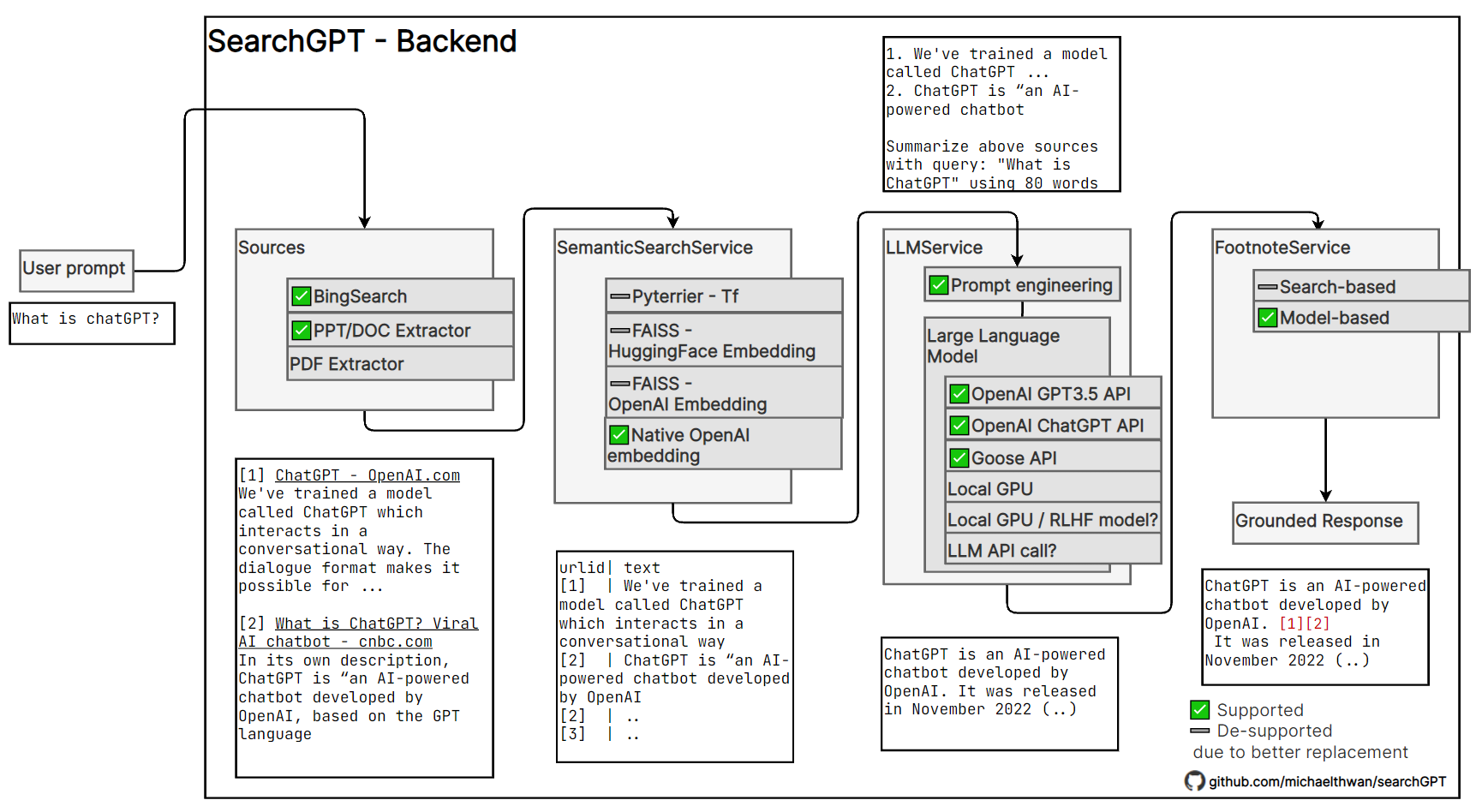
微软bing 的搜索,通过自动汇总多篇文档,直接给出 query 答案,附带给出脚注参考。
searchGPT