项目背景 分析 K12 相关的教育搜索 query,包括拍照搜题上传的照片,在学科分布中,数学占比最大,呈将近一半左右。再考虑目前在 K12解题产品级应用上 NLP 模型的能力,小学数学作为入手点较为合适,尤为其中的算术文字题。即通过自然语言文本将问题描述清楚,通过加减乘除四则运算,便可求解答案的小学数学应用题。在 NLP 模型进行解答的前置环节,需要判定给定的题目描述是否为 AWP (算术文字题) 问题以及对应考察的知识点类型,比如“鸡兔同笼”、“和差倍”、“归一问题”、“工程问题”、“行程问题”等,便于后续的公式生成、答案生成以及解析生成等。因此是否为 AWP 问题 (二分类) 和知识点分类 (多分类多标签),需要进行建模实现。
项目过程 此项目的模型实现,并不是重点和难点。二分类模型、多标签多分类模型,都是机器学习中的典型场景。唯一可能需要花些心思和精力的点是存在严重类别或标签的不平衡,进而导致长尾类别或标签分布过分稀疏被模型忽略。那么在这些长尾类别和标签上,精度和召回都会偏低。这个问题既可以通过 loss 的构建 ( focal loss、asymmetric loss)进行缓解,也可以通过稀疏类别和稀疏标签的上采样数据增强进行缓解,还可以通过难样本挖掘等进行缓解。 ( 注:Asymmetric Loss For Multi-Label Classification 论文 )
此项目重点和难点,在于标准定义和数据集的构建上。标准定义包括,业务目标场景归化到 AWP 问题的标准定义、AWP 问题自身的标准定义、小学数学应用题涉及的知识点多类别定义、多标签定义;数据集构建包括,AWP 问题分类训练数据集中负样本的构建、知识点分类中的不同类别、不同标签对应多少样本比例的构建,以及最终能够准确反映线上收益的测试集和评估业务指标的构建。
标准定义 业务目标场景归化到 AWP 问题定义 该项目的业务目标是针对用户上传的有解题需求的 query (包括拍照搜题)中的小学数学应用题,能够给出公式、解题步骤、答案和解析。主要收益来自于返回的自然搜索结果和拍照搜题中的题库未覆盖到的用户查询 query,或者是查询结果质量偏低,只是近似题不是原题等场景,从而利用 AI 解题能力提高用户体验。因此,将此业务目标场景归化到 AI 解答 AWP 问题。
AWP 问题定义 能够通过四则运算和简单的一元一次方程获取答案的数学文字题,标准细化:
答案必须是数值;
该答案数值可以通过四则运算或一元一次方程求解得到;(大于、小于、比较、取余都作为非 AWP 问题。)
主要为应用题(语言或文字叙述有关事实),有一定的场景设定,“列式计算”、“解方程”等作为非 AWP 问题,凡是需要文字以外的信息才可以作答的,“如图、如表”等,也作为非 AWP 问题;
多个小问需要拆开,所有子问题都是 AWP 问题,整体才可以作为 AWP 问题。
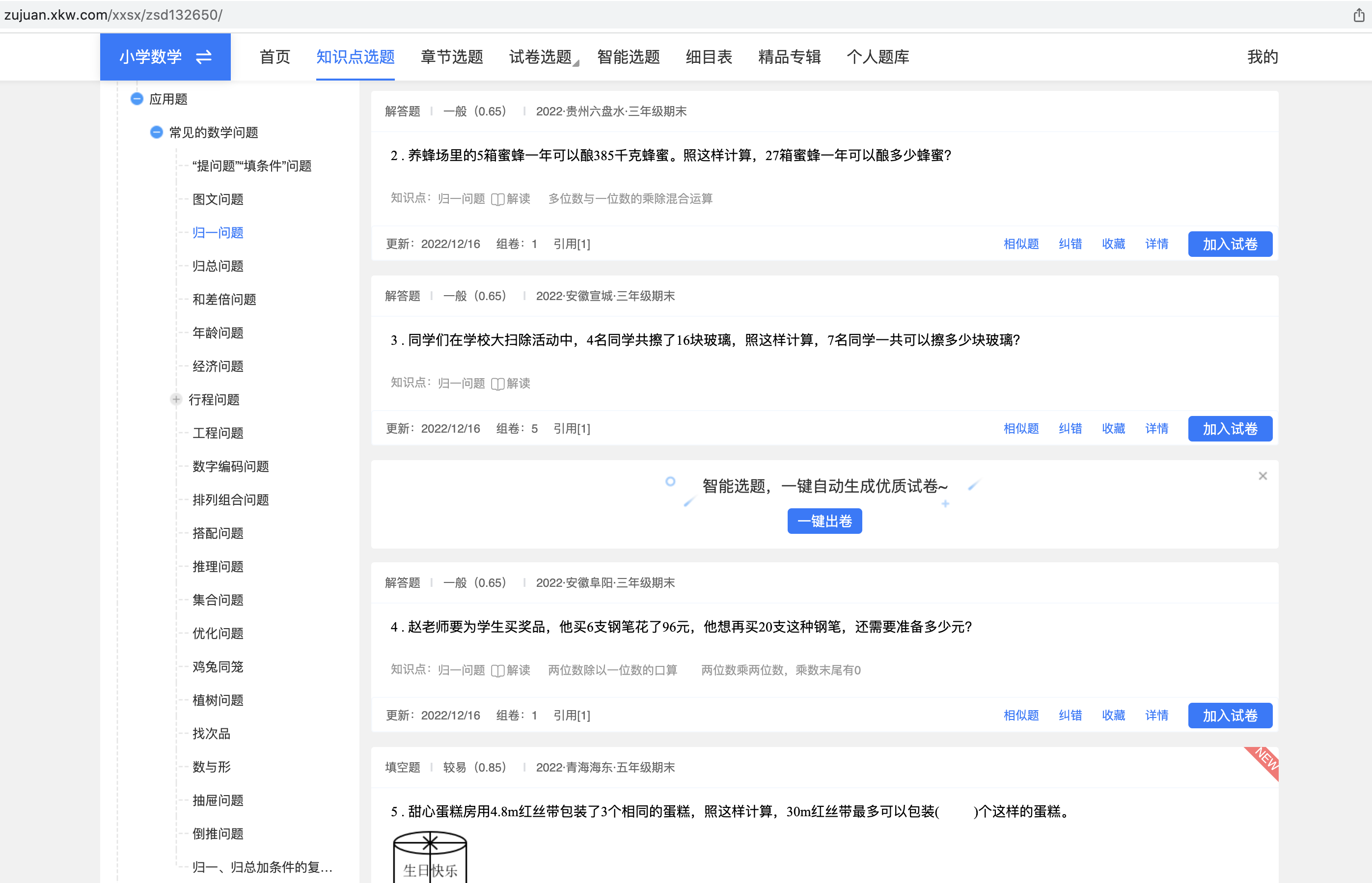
小学数学应用题涉及的知识点——类别定义及标签定义 知识点体系参考来源: https://zujuan.xkw.com/xxsx/zsd132650/
一个题目下的知识点既有应用题类型,如“归一问题”,又有“多位数与一位数的乘除混合运算”标签
抓取题目数据及知识点,结合目录,整理出所有知识点信息,对知识点统一进行盘点
梳理知识点信息,将应用题的类型和涉及知识点的标签分离开来,能归一的归一,能合并的合并
梳理原则1,类别能够反映出解题公式的统一范式,比如“鸡兔同笼”、“植树问题”,一道题目也可能对应多个类别
梳理原则2,标签更多反映描述题目运算或者题目本身信息,标签进行归一,比如“多位数与一位数的乘除混合运算”、“多位数与一位数的加减混合运算”、“多位数与一位数的四则混合运算”,确保标签之间语义互斥,在归一后的标签体系中,一道题目可以对应零、一种或多种标签
实际情况中,确实存在很难进行鉴别的 term ,是划归在类别体系还是划归在标签体系,收集有争议,模糊不清的 term,从用户 query 视角,分析用户使用这些 term 的习惯,权衡折中。进行类别和标签体系的建设,本质是为了能够将这些信息透传给下游公式生成模块,让 AI 模型能够根据类别和标签更好地生成公式。
数据集构建 AWP 问题分类训练数据集中负样本的构建 此样本集需要根据实际模型训练迭代情况,进行调整,大概来源几个方面:
线上服务的 query (包括对照片经过 OCR 识别的到的文本),涉及到的小学数学题目非 AWP 问题进行采样
非四则运算或一元一次方程能够解决的题目,包括图文、图表题目,直接列式计算、解方程的题目,涉及到比较、取余的题目
非小学数学题目
知识点分类中的不同类别、不同标签对应多少样本比例的构建 此样本集需要根据实际模型训练迭代情况,进行调整,大概来源几个方面:
组卷网的目录数据获取、题目以及涉及的知识点获取
菁优网的目录数据获取、题目以及涉及的知识点获取
根据实际情况以及下游 AI 公式生成模块的需要,上采样或难样本挖掘某些长尾类别和标签对应的数据
准确反映线上收益的测试集和评估业务指标的构建 由于最终应用到线上服务链路较长,下游接 AI 公式生成等模块,最终得到的结果才服务线上。故无法直接对AWP分类和知识点分类,从线上收益角度评测。所以需要分两块评估。一是线上真正需要解的 AWP 问题的召回;二是真正透传出的正确知识点信息的 AWP 题目占召回目标 AWP 题目的比例。后续结合 AI 公式生成的结果,以及最终的服务性能,做回归验证。
代码参考 ASL 损失 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 import torchimport tensorflow as tfdef torch_asl_loss (x, y) : """" Parameters ---------- x: input logits y: targets (multi-label binarized vector) """ targets = y anti_targets = 1 - y xs_pos = torch.sigmoid(x) xs_neg = 1.0 - xs_pos clip = 0.05 gamma_neg = 4 gamma_pos = 1 disable_torch_grad_focal_loss = False eps = 1e-8 if clip is not None and clip > 0 : xs_neg.add_(clip).clamp_(max=1 ) loss = targets * torch.log(xs_pos.clamp(min=eps)) loss.add_(anti_targets * torch.log(xs_neg.clamp(min=eps))) if gamma_neg > 0 or gamma_pos > 0 : if disable_torch_grad_focal_loss: torch._C.set_grad_enabled(False ) xs_pos = xs_pos * targets xs_neg = xs_neg * anti_targets asymmetric_w = torch.pow(1 - xs_pos - xs_neg, gamma_pos * targets + gamma_neg * anti_targets) if disable_torch_grad_focal_loss: torch._C.set_grad_enabled(True ) loss *= asymmetric_w return -loss.sum() def compute_loss (logits, labels, gamma_pos=1 , gamma_neg=4 , clip=0.05 , eps=1e-8 , ) : labels = tf.cast(labels, dtype=tf.float32) logits_sigmoid = tf.nn.sigmoid(logits) logits_sigmoid_pos = logits_sigmoid logits_sigmoid_neg = 1 - logits_sigmoid_pos if clip is not None and clip > 0 : logits_sigmoid_neg = tf.clip_by_value((logits_sigmoid_neg + clip), clip_value_min=0 , clip_value_max=1.0 ) loss_pos = labels * tf.log(tf.clip_by_value(logits_sigmoid_pos, clip_value_max=1.0 , clip_value_min=eps)) loss_neg = (1 - labels) * tf.log(tf.clip_by_value(logits_sigmoid_neg, clip_value_max=1.0 , clip_value_min=eps)) loss = loss_pos + loss_neg if gamma_neg > 0 or gamma_pos > 0 : pt0 = logits_sigmoid_pos * labels pt1 = logits_sigmoid_neg * (1 - labels) pt = pt0 + pt1 one_sided_gamma = gamma_pos * labels + gamma_neg * (1 - labels) one_sided_w = tf.pow(1 - pt, one_sided_gamma) one_sided_w_no_gradient = tf.stop_gradient([pt0, pt1, pt, one_sided_gamma, one_sided_w]) loss *= one_sided_w_no_gradient return -tf.reduce_sum(loss) def compute_loss_own (logits, labels) : with tf.variable_scope("loss" ): labels = tf.cast(labels, dtype=tf.float32) x_sigmoid = tf.sigmoid(logits) xs_pos = x_sigmoid xs_neg = 1 - x_sigmoid clip = 0.05 gamma_neg = 4 gamma_pos = 1 eps = 1e-8 if clip is not None and clip > 0 : xs_neg = tf.clip_by_value(xs_neg + clip, clip_value_min=-1 , clip_value_max=1 ) los_pos = labels * tf.log(tf.clip_by_value(xs_pos, clip_value_min=eps, clip_value_max=1e8 )) los_neg = (1 - labels) * tf.log(tf.clip_by_value(xs_neg, clip_value_min=eps, clip_value_max=1e8 )) loss = los_pos + los_neg if gamma_neg > 0 or gamma_pos > 0 : pt0 = xs_pos * labels pt1 = xs_neg * (1 - labels) pt = pt0 + pt1 one_sided_gamma = gamma_pos * labels + gamma_neg * (1 - labels) one_sided_w = tf.pow(1 - pt, one_sided_gamma) loss *= one_sided_w return tf.reduce_sum(-loss) if __name__ == "__main__" : logits = [] labels = []