SpeechGPT
SpeechGPT: Empowering Large Language Models with Intrinsic Cross-Modal Conversational Abilities
论文 Review
多模态大型语言模型被认为是迈向通用人工智能(AGI)的关键一步,随着ChatGPT的出现引起了极大的兴趣。然而,当前的语音语言模型通常采用级联范式,阻止了模态间知识转移。在本文中,我们提出了SpeechGPT,这是一种具有内在跨模态对话能力的大型语言模型,能够感知和生成多模型内容。对于离散语音表示,我们首先构建了SpeechInstruct,这是一个大规模的跨模态语音指令数据集。此外,我们采用三阶段训练策略,包括模态适应预训练、跨模态指令微调和模态链指令微调。实验结果表明,SpeechGPT具有令人印象深刻的遵循多模态人类指令的能力,并突出了用一个模型处理多种模态的潜力。
我们使用自监督训练的语音模型执行语音离散化,以统一语音和文本之间的模态。然后将离散语音标记扩展到LLM的词汇表中,从而赋予模型感知和生成语音的固有能力。
To provide the model with the capacity to handle multi-modal instructions, we build the first speechtext cross-modal instruction-following dataset SpeechInstruct. 具体来说,我们将语音离散化为离散单元(Hsu 等人,2021 年),并根据现有的 ASR 数据集构建跨模态单位文本对。同时,我们使用 GPT-4 为各种任务构建了数百条指令,以模拟附录 B 中所示的实际用户指令。此外,为了进一步增强模型的跨模态能力,我们设计了模态链指令数据,即模型接收语音命令,在文本中思考过程,然后在语音中输出响应。
For better cross-modal transfer and efficient training, SpeechGPT undergoes a three-stage training process: modality-adaptation pre-training, cross-modal instruction fine-tuning, and chain-of-modality instruction fine-tuning. The first stage enables speech comprehension for SpeechGPT with the discrete speech unit continuation task. The second stage employs the SpeechInstruct to improve the model’s cross-modal capabilities. The third stage utilizes parameter-efficient LoRA (Hu et al., 2021) fine-tuning for further modality alignment.为了更好的跨模态迁移和高效的训练,SpeechGPT经历了三个阶段的训练过程:模态适应预训练、跨模态指令微调和模态链指令微调。第一阶段通过离散语音单元延续任务启用 SpeechGPT 的语音理解。第二阶段使用 SpeechIninstructions 来提高模型的跨模态功能。第三阶段利用参数高效的 LoRA (Hu 等人,2021 年)微调以进一步调整模态。
To evaluate the effectiveness of SpeechGPT, we conduct a wide range of human evaluations and case analyses to estimate the performance of SpeechGPT on textual tasks, speech-text cross-modal tasks, and spoken dialogue tasks. The results demonstrate that SpeechGPT exhibits a strong ability for unimodal and cross-modal instruction following tasks as well as spoken dialogue tasks.
Multi-modal Large Language Model. LLaVA (Liu et al., 2023) leverages pre-trained CLIP (Radford et al., 2021) visual encoder and LLaMA (Touvron et al., 2023) and conduct instruct tuning on GPT4-assisted visual instruction data. However, such structures only enable LLMs to process multi-modal input, without ability to generate multi-modal output. Diverging from prior studies, our approach emphasizes the development of a speech-centric multi-modal LLM, endowing it with the proficiency to accommodate both multi-modal input and output.
随着 ChatGPT 的出现,一些研究集中在专家语音模型与 LLM 的集成上,以实现与 LLM 的直接语音交互。 HuggingGPT(Shen 等人,2023 年)促进了 LLM 对人类指令的任务分解,并允许从 Huggingface 调用模型来完成特定任务,包括一系列自动语音识别 (ASR) 和文本到语音转换模型。AudioGPT(Huang 等人,2023a)利用各种音频基础模型来处理复杂的音频信息,并将 LLM 与输入/输出接口(ASR、TTS)连接以进行语音对话。然而,这些模型表现出更高的复杂性,需要大量的资源,并且容易出现不可避免的错误累积问题。我们的方法可以在不依赖ASR或TTS系统的情况下与LLM进行语音交互,从而规避了上述缺点。
we construct SpeechInstruct, a speech-text cross-modal instruction-following dataset. This dataset consists of two parts, the first part is called Cross-Modal Instruction, and the second part is called Chain-of-Modality Instruction.
我们使用mHuBERT2作为语音标记器,将语音数据离散化为离散单元,并删除相邻帧的重复单元以获得简化单元。最终,我们获得了 900 万个单元文本数据对。
我们生成与语音-文本数据对兼容的 ASR 和 TTS 任务描述。与自我指导方法不同(Wang 等人,2022 年),我们通过零镜头方法生成描述。具体来说,我们直接将附录 A 中显示的提示输入到 OpenAI GPT-4 中以生成任务描述。我们的生成方法为每个任务产生 100 条指令,附录 B 中显示了一些示例。
对于离散单元序列 U 及其关联的转录 T,我们根据概率 p 确定它是用于构建 ASR 任务还是 TTS 任务。随后,我们从相应的任务描述中随机选择一个描述 D。这将产生一个由任务描述、离散单元序列和转录组成的三元组,表示为 (D, U, T)。在此之后,三元组使用模板组装成指令:[Human]:{D}。 这是输入:{U}
As a result, we obtained 37,969 quadruplets composed of speech instructions, text instructions, text responses, and speech responses, denoted as (SpeechI, T extI, T extR, SpeechR).
discrete unit extractor, large language modal and unit vocoder.
with K denoting the total number of clusters.
LLaMA
由于单扬声器单元声码器的限制(Polyak 等人,2021 年),我们训练了一个多扬声器单元 HiFi-GAN 来解码来自离散表示的语音信号。HiFi-GAN架构由一个生成器G和多个鉴别器D组成。生成器使用查找表(LUT)嵌入离散表示,嵌入序列由一系列由转置卷积和具有膨胀层的残差块组成的块进行上采样。扬声器嵌入连接到上采样序列中的每个帧。鉴别器具有多周期鉴别器 (MPD) 和多尺度鉴别器 (MSD),它们的架构与(Polyak 等人,2021 年)相同。
To incorporate speech discrete representation into LLM, we expand the vocabulary and corresponding embedding matrix first.
The first stage is ModalityAdaptation Pre-training on unpaired speech data. The second stage is Cross-modal Instruction Fine-Tuning. The third stage is Chain-of-Modality Instruction Fine-Tuning.
Stage 1: Modality-Adaptation Pre-training To enable LLM to handle discrete units modality, we utilize an unlabeled speech corpus to train LLM in a next-token prediction task.
Stage 2: Cross-modal Instruction Fine-Tuning In this stage, we align speech and text modalities utilizing paired data.
Stage 3: Chain-of-Modality Instruction Fine-Tuning After obtaining the model in stage 2, we utilizes parameter-efficient Low-Rank Adaptation (LoRA) (Hu et al., 2021) to fine-tune it on Chain-ofModality Instruction in SpeechInstruct. We add LoRA weights (adapters) to the attention mechanisms and train the newly added LoRA parameters. We adopt the same loss function as stage 2.
尽管 SpeechGPT 表现出令人印象深刻的跨模态指令跟随和语音对话能力,但它仍然存在一定的局限性:1) 它不考虑语音中的副语言信息,例如无法以不同的情感语调生成响应,2) 它需要在生成基于语音的响应之前生成基于文本的响应,3) 由于上下文长度限制, 它无法支持多回合对话。
这项工作提出了SpeechGPT,一种固有的跨模态多模态大语言模型,能够感知和生成多模态内容。此外,为了缓解当前语音域中指令数据集的稀缺性,我们提出了SpeechInstruct。第一个语音-文本跨模态指令-跟随数据集包含基于模态链机制的跨模态指令数据和口语对话数据。为了获得改进的跨模态性能,我们采用三阶段训练范式来获得最终的 SpeechGPT。实验结果表明,SpeechGPT在各种单模态或跨模态任务中取得了有希望的结果,并证明了将离散语音令牌组合到语言模型中是一个有希望的方向。
论文提炼
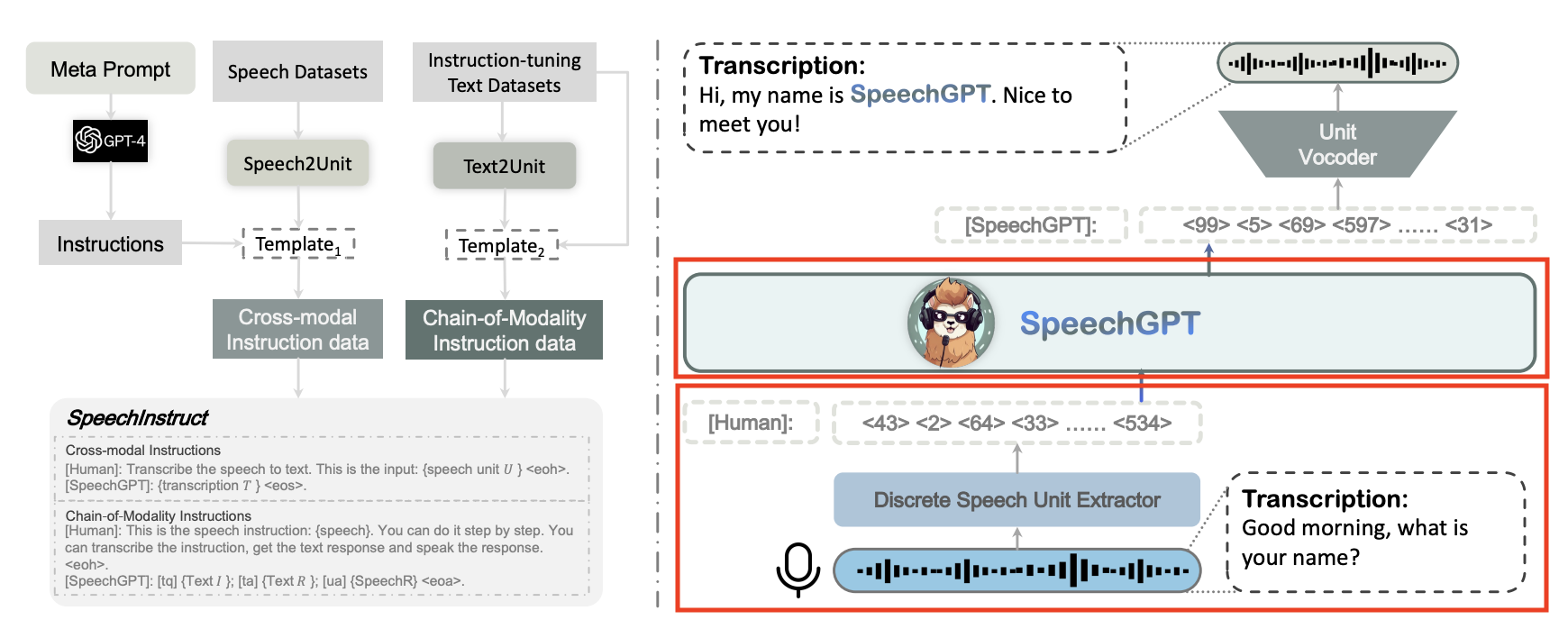
- 在离散化语音单元抽取器(discrete unit extractor) 中,将语音利用 HuBERT 和 K-means 算法,映射为离散化的语音单元序列(语音单元字表大小为 K)
- 用语音单元字表对 LLM 的字表进行扩展,使 LLM 能够处理语音单元
- 结合自然语言文本和待处理的某条待处理语音的离散化的语音单元序列,构造 prompt ,输出 LLM ,得到目标语音对应文本,完成 ASR 任务
- 经历了三个阶段的训练过程:模态适应预训练、跨模态指令微调和模态链指令微调