儿童双语场景下的LLM+ASR思路
项目背景
LLM 时代,天猫精灵,作为智能家居的典型应用,在语音命令驱动模式上加持 LLM 的智能和相关第三方生态和插件,有广阔的发展前景。其中,听清听懂用户的语音指令是重要基础,此外更为实时精准的语音识别系统(ASR)对用户体验也是至关重要。然而在智能早教中的儿童双语场景,ASR 一直被视为业界难题。原因如下(不限):
- 儿童相较于成人,身体结构不同,声线吐字导致语音语言特性不同,此外语音、文字、语言学习也不完善,诸如种种,有着天然的技术辨别难度;
- 儿童说话习惯也与成人不同,包括且不限于语速较慢、常留尾音等,也给现有ASR系统造成一定困难;
- 双语多语场景(包括方言),语种所对应的语音迥异,在音素上有很大不同,当混合着多语言输入,挑战加大;
- 现有ASR数据多为成人语音数据,儿童语音数据的缺乏,ASR针对儿童语音建模,数据缺乏导致模式缺陷。
智能早教中,尤其双语,相较文字语言的缺乏,语音可以发挥更大空间。场景利用更为丰富,包括不限于:
- 互动语言学习:针对语音发音,进行实时评测和纠正,提升学习效果
- 互动场景语音交互,提升少儿语言学习能力
利用 LLM 在句段核心语义理解的智能,结合用户对话机制的设计和 Langchain 工程实现,尽可能解决儿童双语 ASR 问题,让用户体验更流畅可控。
项目调研
现有人机交互ASR系统及产品解决方案:https://www.woshipm.com/ai/4144034.html;
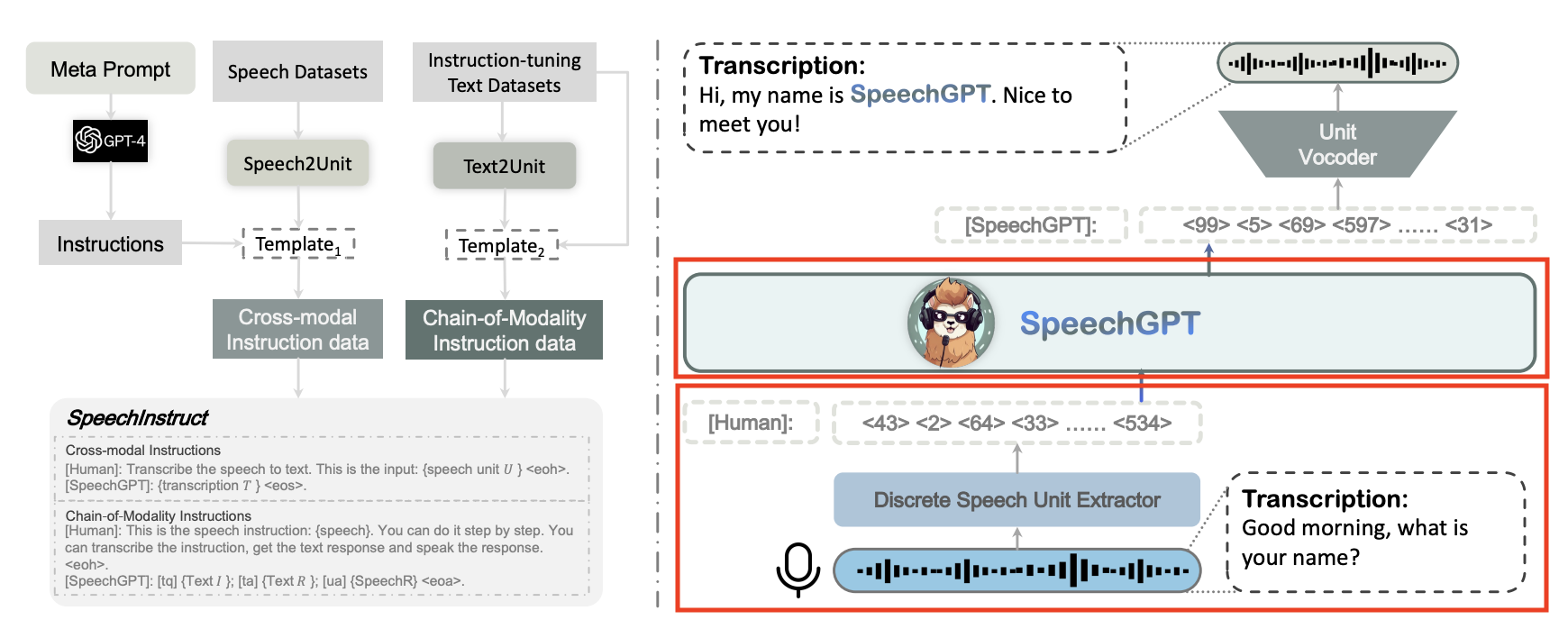
SpeechGPT,最新结合LLM,针对语音模态,具有内在的跨模态对话能力,能够感知语音和生成语音内容;
S4, Efficiently Modeling Long Sequences with Structured State Spaces , S4,具有长序列建模天然优势的S4架构。
STRUCTURED STATE SPACE DECODER FOR SPEECH RECOGNITION AND SYNTHESIS,比起transformer,利用S4架构,天然优势适配超长序列,在ASR领域已有典型应用,有着更快的计算效率、推理速度和更大的序列长度空间、更高的性能;
Beit 系列技术详解,将图像模态数据 tokenizer 处理,转换成 Token 序列
拟解决方案
基本架构
针对ASR系统,采用SpeechGPT的离散化语音单元抽取器(discrete unit extractor)和LLM(红框部分)。
性能优化及提高
针对儿童语音数据的缺乏
尽量收集,只要是儿童语音数据,不管是单语言、混合语言,还是单语音模态,还是语音-文本pair对齐多模态,都是需要的。
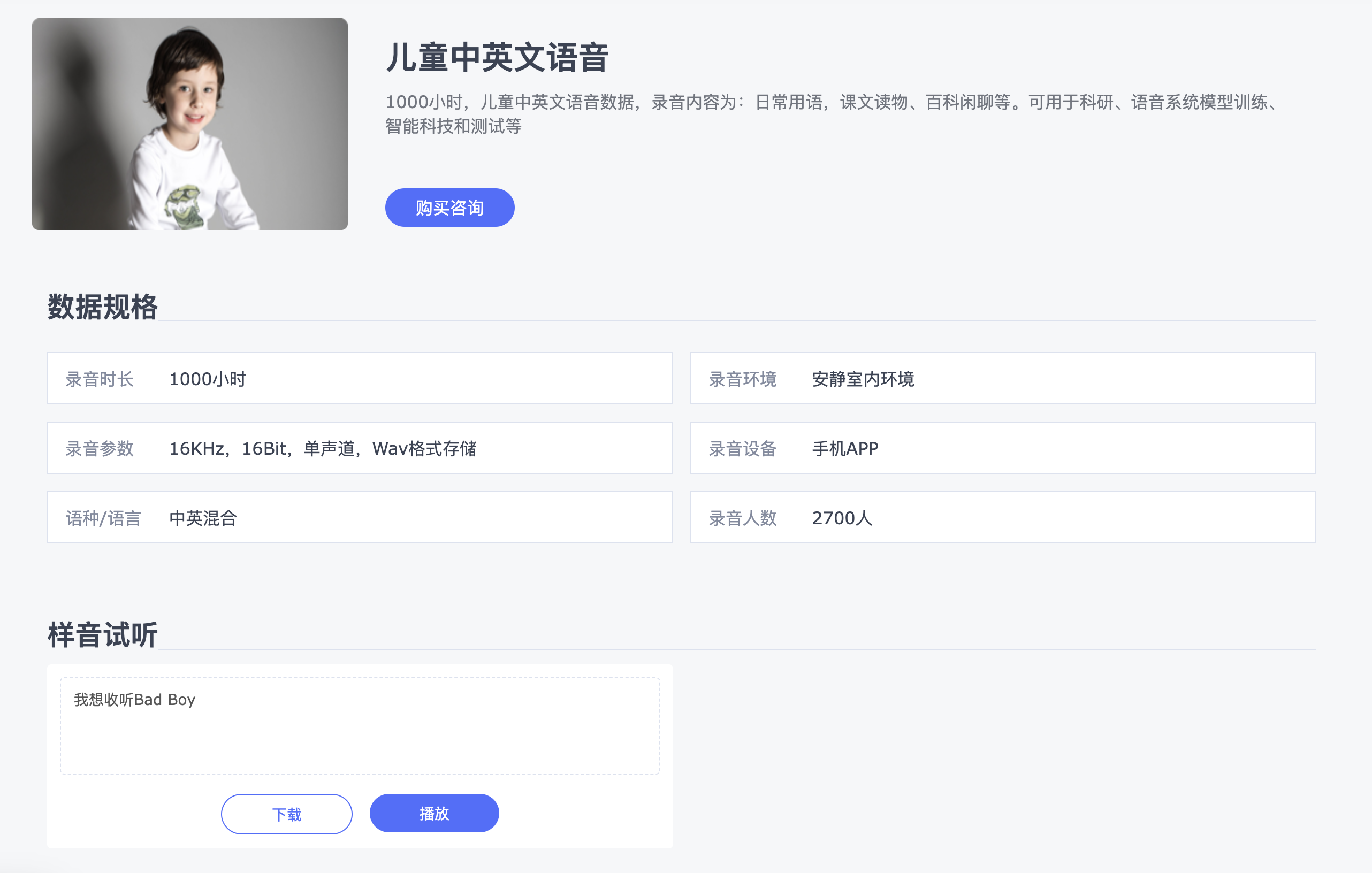
儿童中英混合语音,通过手机APP在安静环境下,录制2700人,共计1000小时,录音内容为日常用语,课文读物、百科闲聊等。https://www.data-baker.com/data/index/distinguish
针对儿童、双语场景的 ASR 模型算法优化
利用收集到的儿童语音数据(单语言、多语言、单语音模态),针对SpeechGPT中用K-means获取语音单元字表的方法,借鉴Beit系列中图像Tokenizer的VQ-VAE的思路,换用性能更优的基于自监督的VAE码本构建思路,将原HuBERT 已有的成人语音字表再次进行重训和扩充,最终获得在成人语音基础上适配儿童目标双语,甚至多语的语音单元字表;
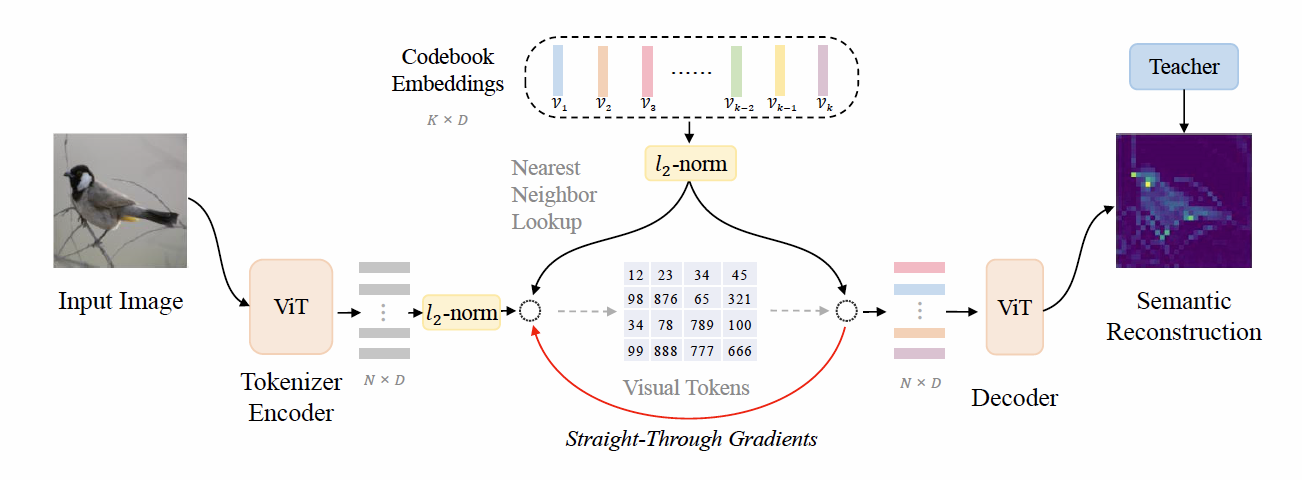
利用收集到的儿童语音数据(语音-文本pair对齐多模态),借鉴Beit系列在loss构建的优化,逐步将离散化语音单元抽取器形成的语音元素序列特征表征融入后续loss计算,整体优化全局的loss,包括ASR目标损失和语音元素序列表征损失,从而继续优化码本字表和离散化语音单元抽取器的抽取语音元素序列的能力;
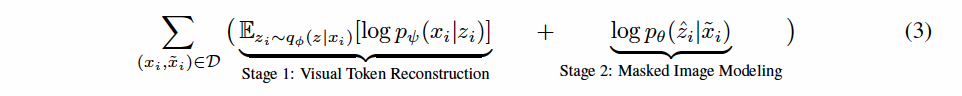
整个过程采用SpeechGPT的Cross-modal Instruction的prompt构建模式,结合儿童双语环境下的场景要求优化prompt工程,结合gpt-4构建指令,比如,“下面是一段儿童朗读古诗的语音,可能存在发音模糊不准的情形,请仔细辨认并给出最可能准确的文本,适当允许用近似读音的字词替换:xxx”等;
采用其预训练和跨模态指令微调,在儿童语音场景的单语言语音、多语言语音、单语音模态数据上进行Next Token预训练;在语音-文本pair对齐多模态数据上进行跨模态指令微调;
在模型推理时,获取到ASR的文本识别结果,条件允许时,可以再充分利用LLM对文本纠错的能力,一定程度上缓解 ASR 字错率。当然也可以结合prompt优化工作,比如“下面这段文本中可能由于发音不准或近似模糊,会有一些错别字,请结合上下文语义纠正过来,正确的文本是:xxx”,NLP领域中,文本纠错数据集也可以加以利用。
ASR 模型可控
- 进行场景针对优化,得到儿童双语场景中能够胜任的ASR模型,部署云端
- 结合LangChain,模型前置上部署一些简单的过滤门控机制,比如从语音频率、音色等多个维度判断,决定调用ASR服务路由,符合条件则调用相关ASR服务,在之后,可以再一些兜底机制,比如当给出的ASR解码文本置信度很低时,考虑是否走一次文本纠错,或者其他兜底链路,提高可控性。
结合多轮对话优化
- SpeechGPT对语音/文本两种序列模态融合,在多轮对话场景要求更大序列长度,寻求S4架构彻底解决
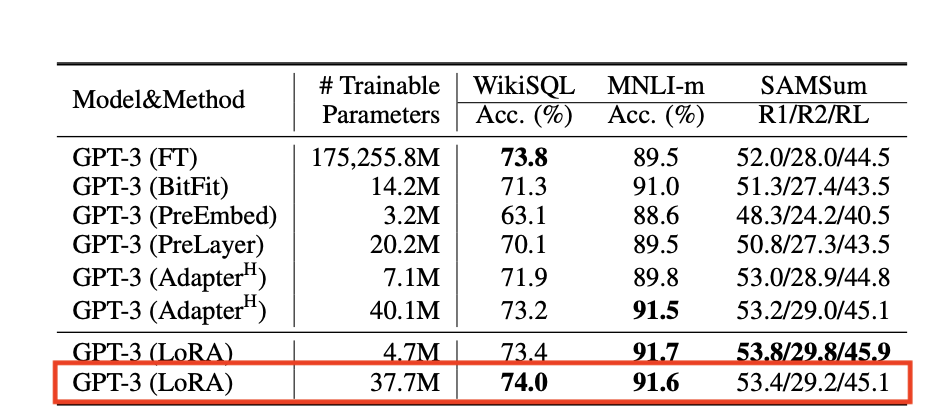
Lora 私人定制化ASR+LLM服务(成本允许条件下,偏脑洞)
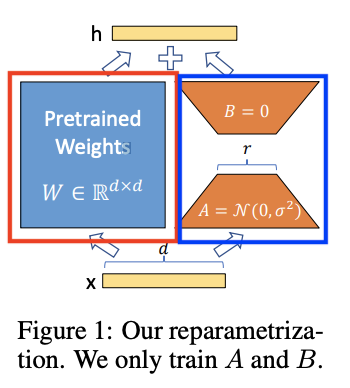
Lora Low-Rank Adaptation of Large Language Models
将ASR+LLM冻结在云端,终端放置私人订制的 Lora 矩阵,进行适配
有待确认终端是否具备放置Lora矩阵的内存、以及计算能力(lora矩阵和传输来的云端冻结的ASR+LLM输出向量进行计算)
通信开销(云端冻结ASR+LLM输出向量开销)
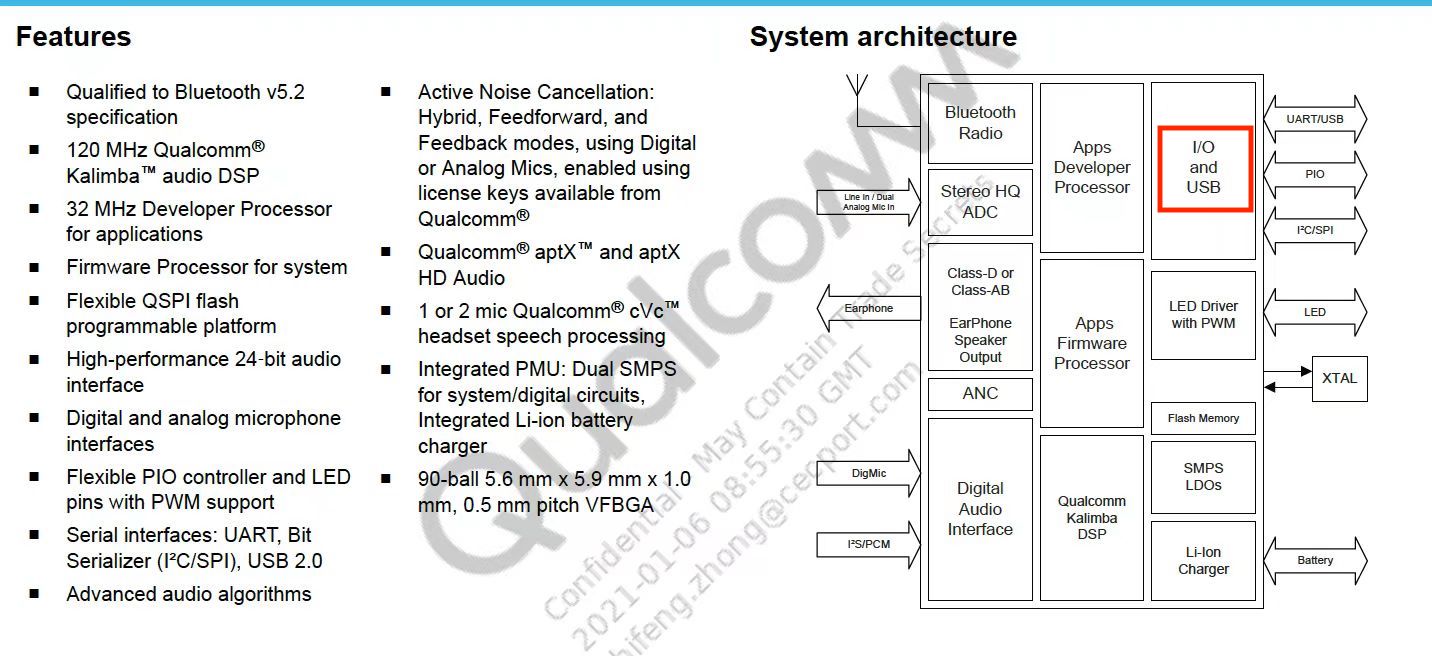
智能音响(天猫精灵)、蓝牙耳机等主流成熟芯片了解,可以通过 I/O 口将语音数据透传出,用于处理计算
高通 QCC3040