s4
Efficiently Modeling Long Sequences with Structured State Spaces
论文Review&提炼
主要解决:超长时间序列的 Seq2Seq
存在一类任务,长时依赖任务,就是序列长度很长 long-range arena (LRA),其中 Path-X ,序列长度为 128 * 128 = 16384 ,现有的 Seq2Seq 模型都无法解决(比随机猜测还差),LRA 基准: https://github.com/google-research/long-range-arena
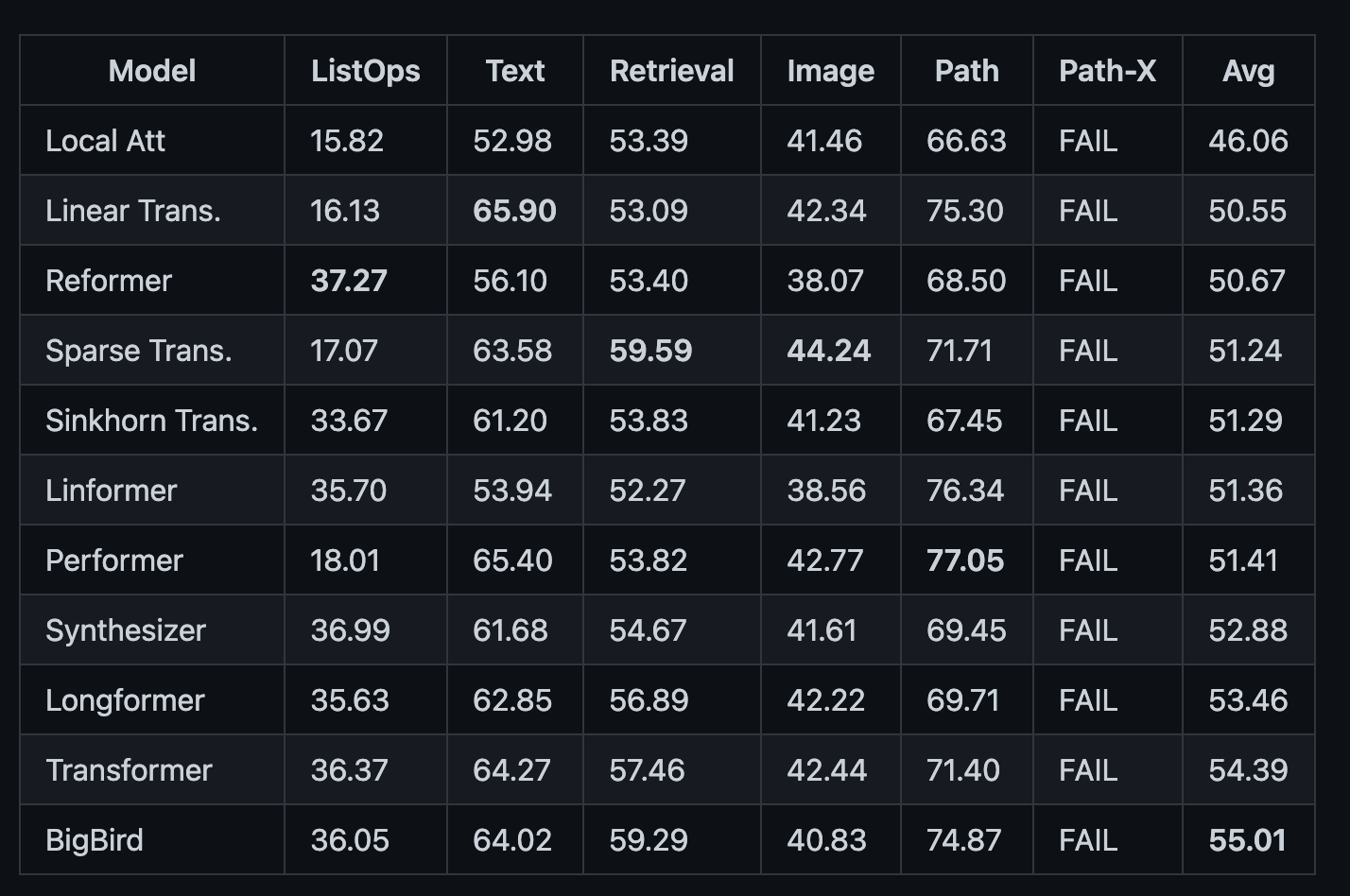
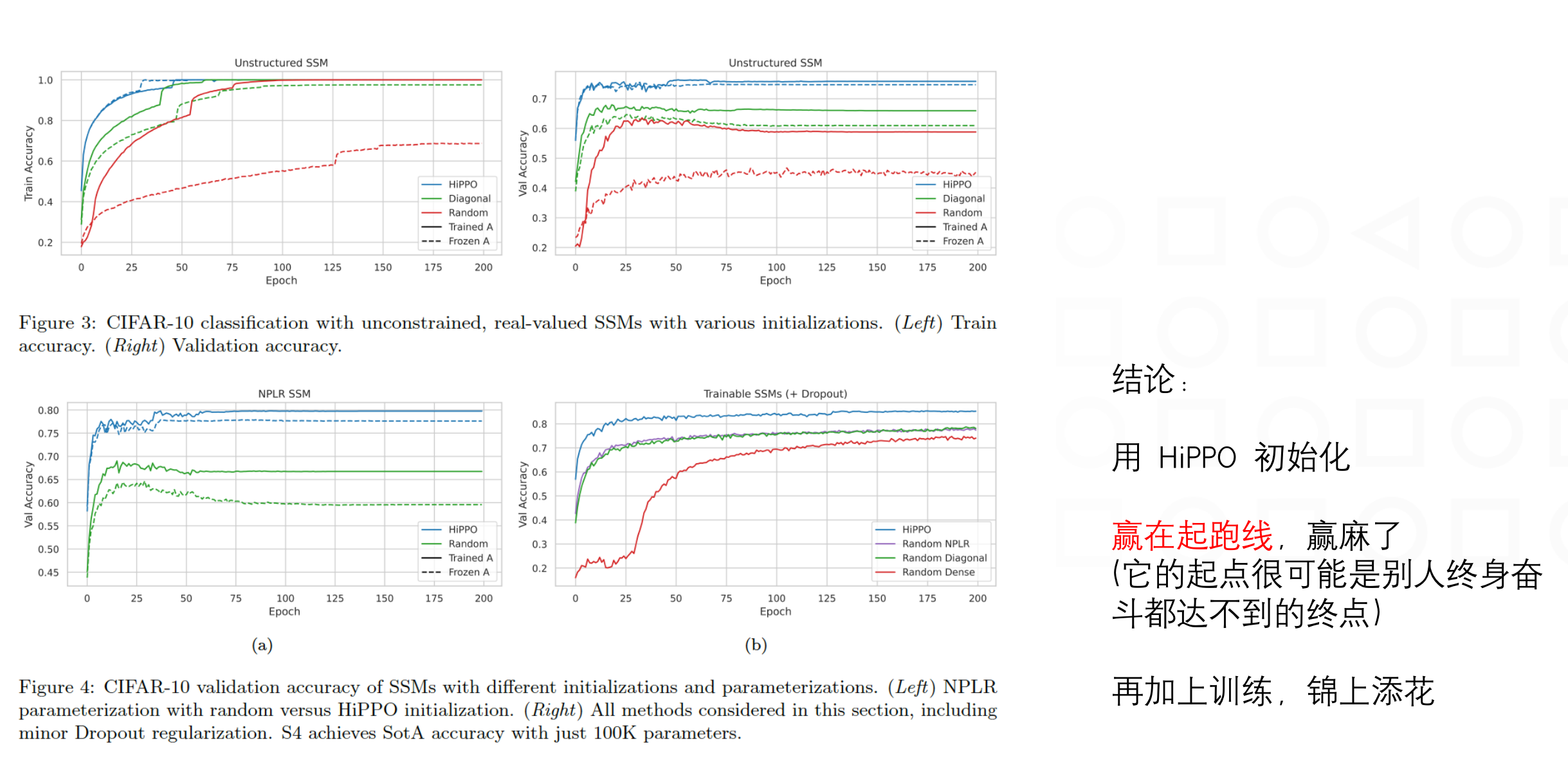
S4 效果,LRA 任务集,某些任务指标精度上,接近transformer指标的 Double,在16384 序列长度的Path-X 达到了 88.10
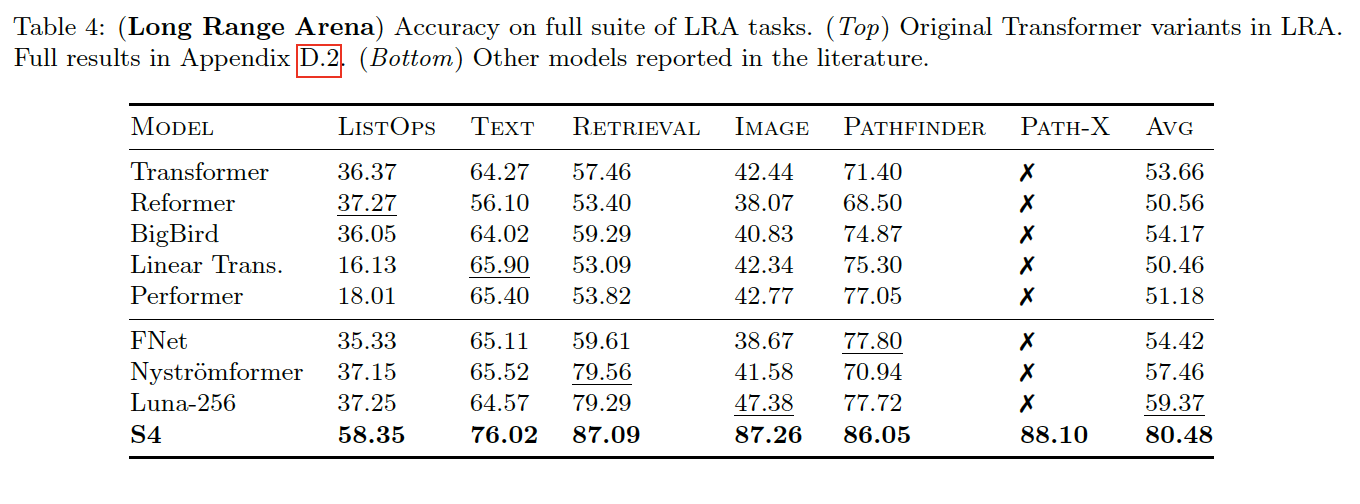
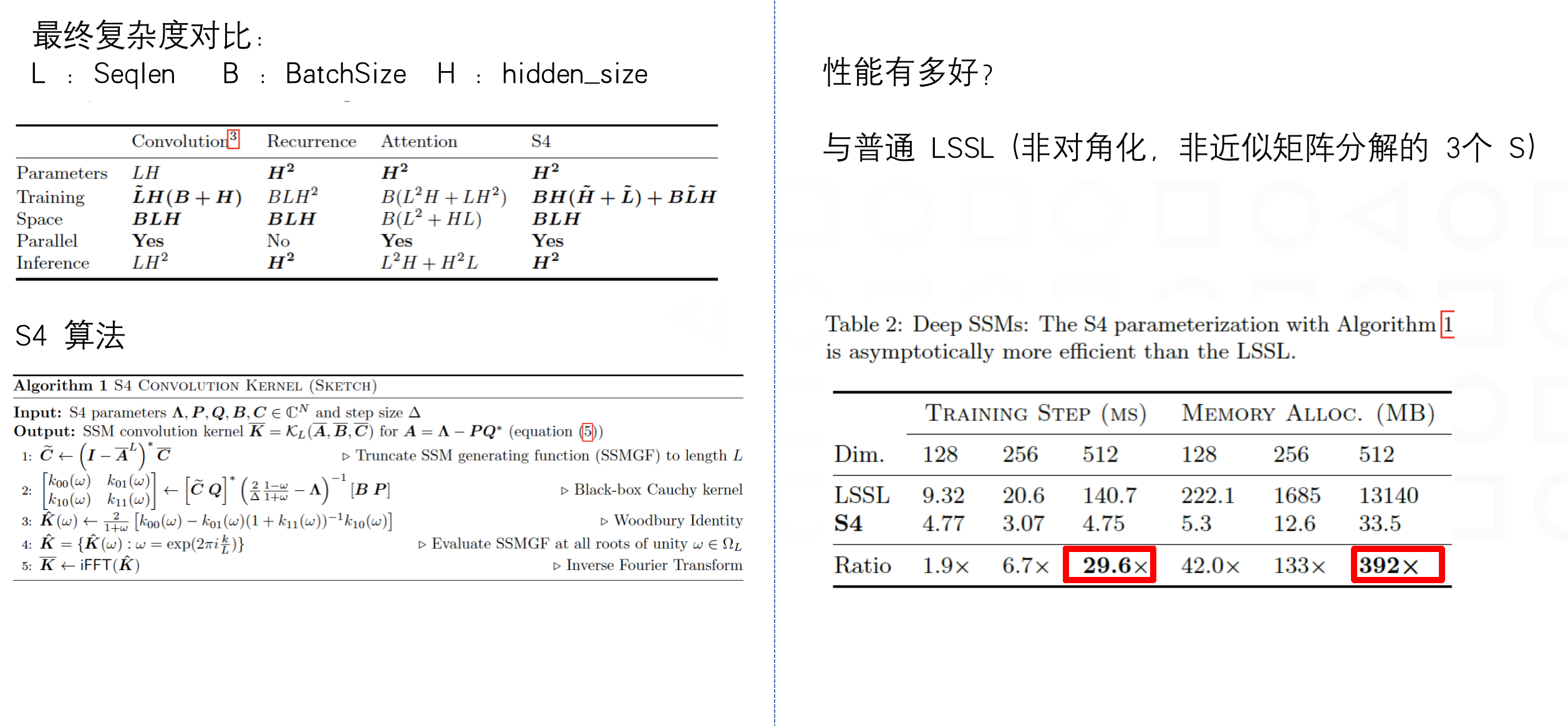
且 S4 在 1 维像素级别的图像分类、音频分类、CIFAR-10 密度估计、WikiText-103 language modeling 语言模型上,指标基本打平和优于 sota ,但在性能上,推理速度上,成倍地提高,且输入序列越长,S4 加速效果越明显,在时间、空间上均胜过 transformer
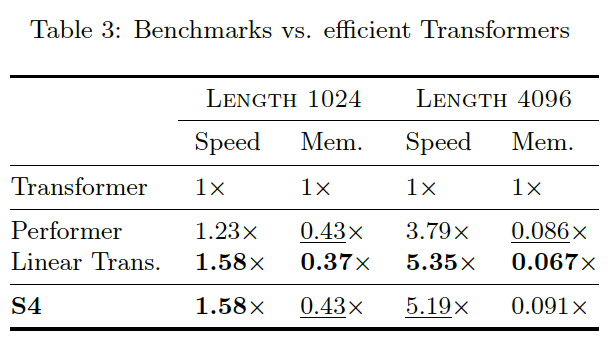
S4 = SSM + HiPPO + Structured Matrices 其中,SSM: State Space sequence model(状态空间序列模型);HiPPO: High-order Polynomial Projection Operators(高阶多项式投影算子);Structure Matrices 负责对 SSM 中的矩阵做一定限定和优化。
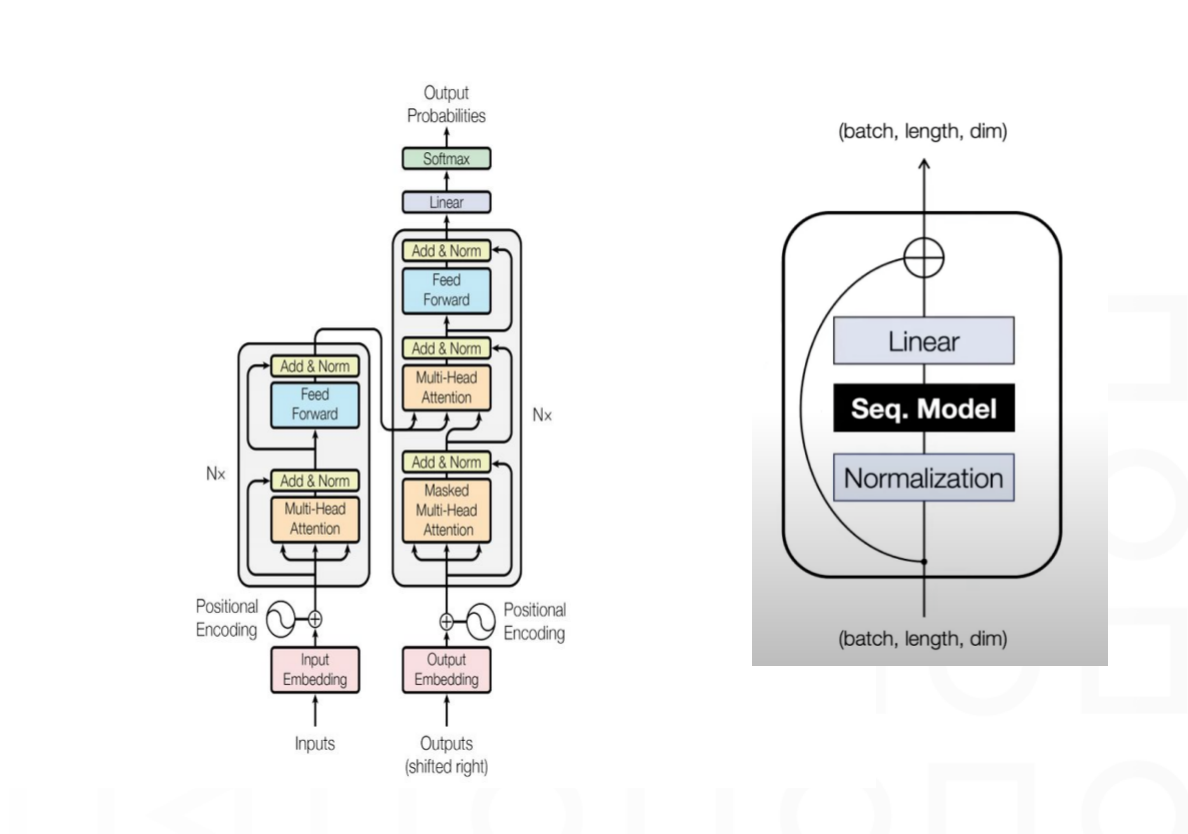
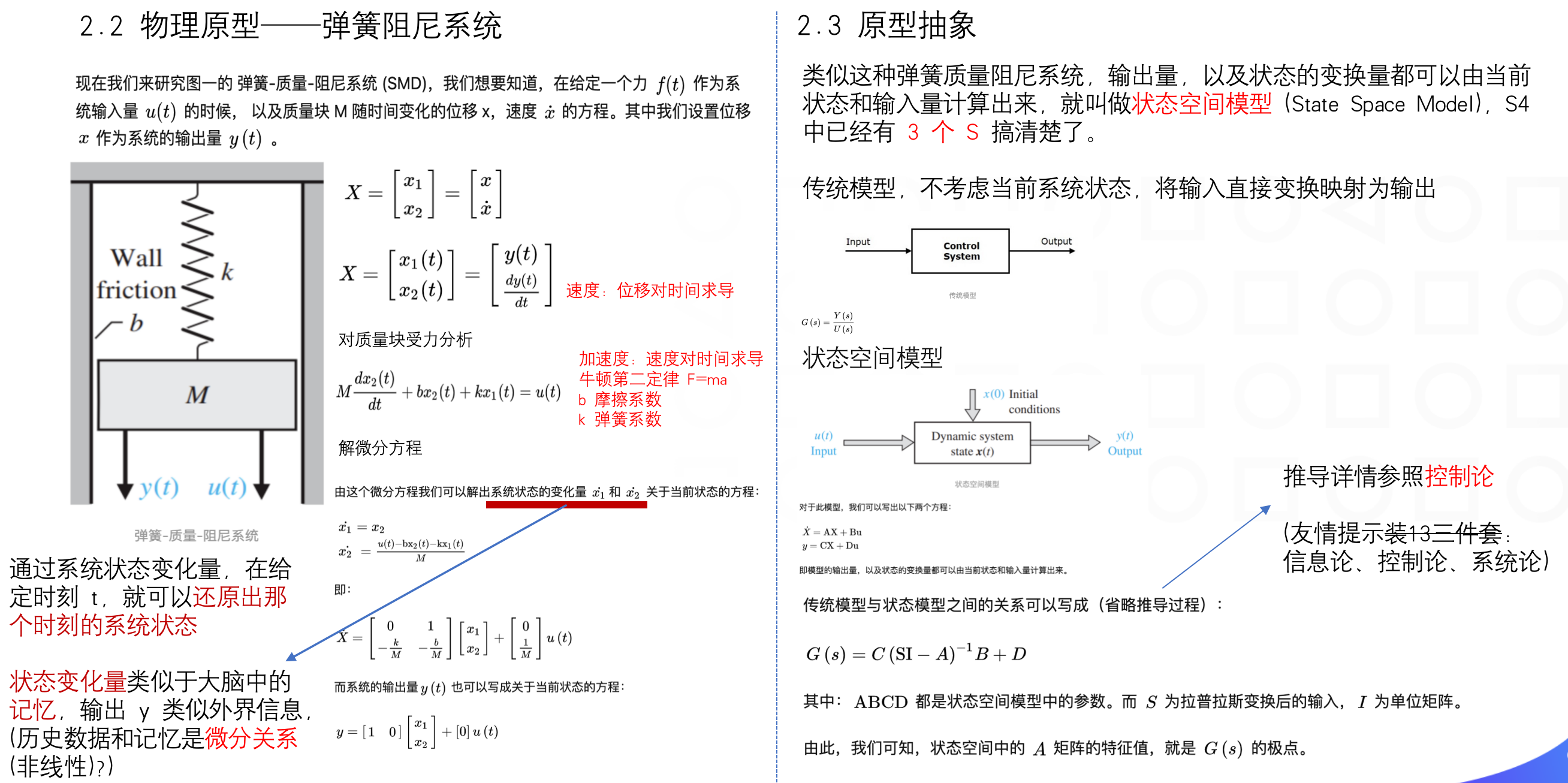
SSM
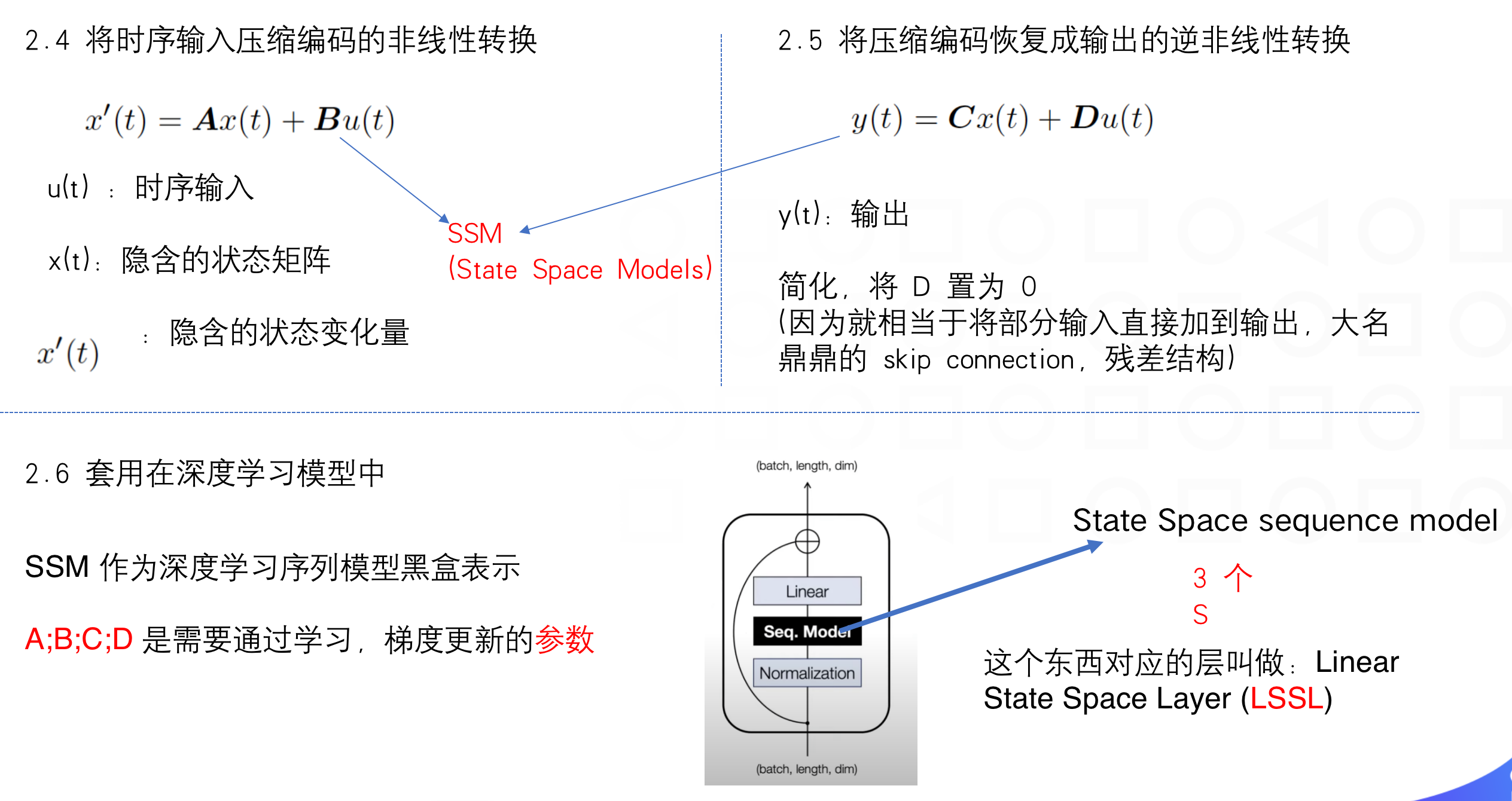
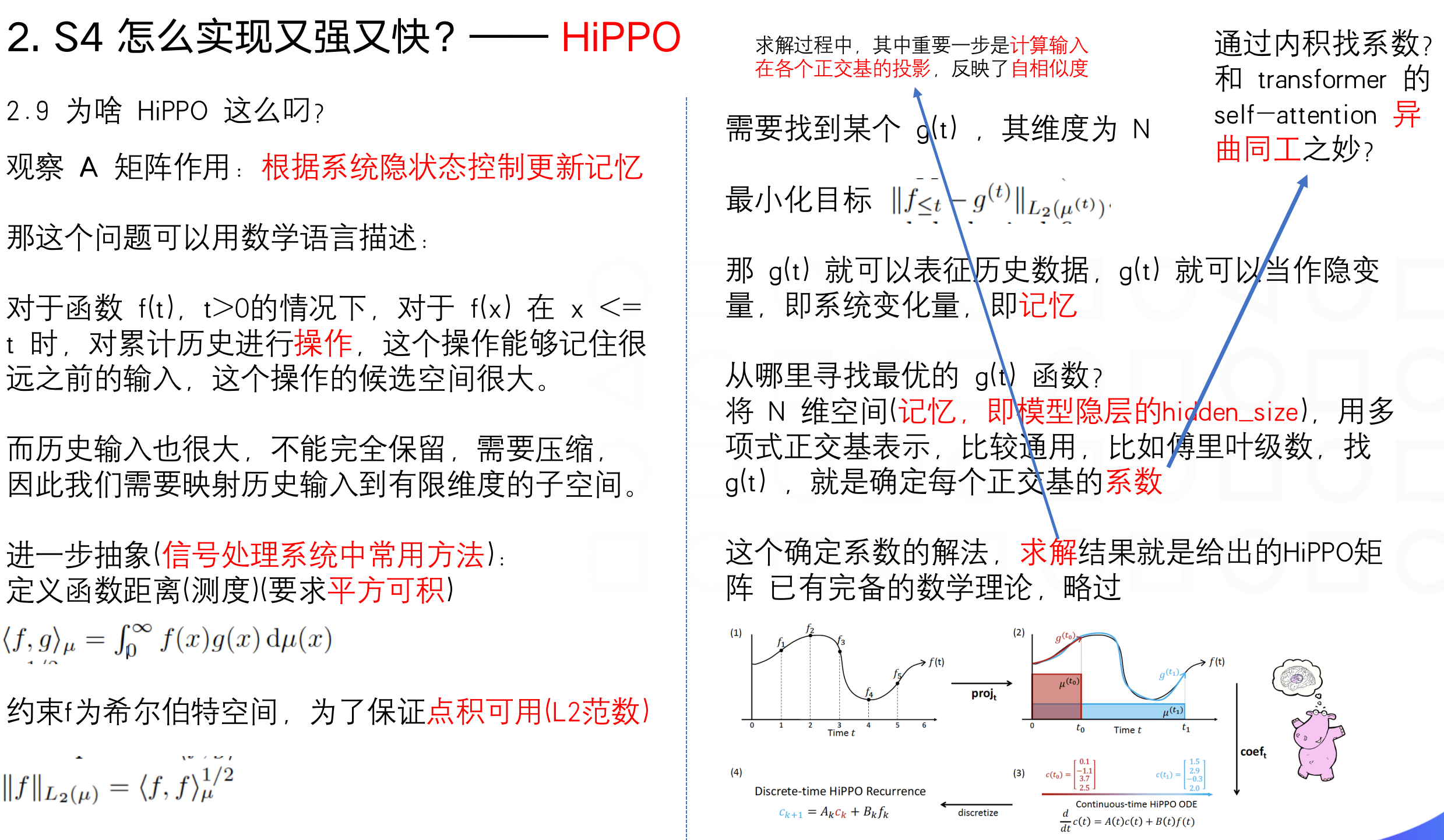
HiPPO


Structured


HiPPO 重要性
S4 model 代码实现

总结
- SSM 统一了 CNN 和 RNN,S4 继承于 SSM,利用 HiPPO 矩阵,又统一了 Transformer 的 Self-Attention
- 能够让 Transformer、S4 对输入数据进行非线性变化压缩编码成记忆,和将记忆解码成输出的数学原理一致,
都是状态空间模型对应的一阶微分方程,区别是寻找非线性变化。而 S4 和 Self-Attention 在寻找非线性变化的
原理也是一致的,利用输入的点积在记忆空间上各维度的投影 - SSM 简化到极致,本质上就是拉弹簧,大道至简
- HiPPO 做的事情,就是让模型变成一根弹簧,能够最大限度地记住历史输入
- 对于深度学习模型,参数初始化是至关重要,除参数初始化之外,也许深度学习并非完全黑盒,不可解释,
背后有着如 HiPPO 类似的数学原理
参考
(分享的主要论文)
Efficiently Modeling Long Sequences with Structured State Spaces
(在 LSSL 框架下统一 RNN、CNN 和连续时序模型)
Combining Recurrent, Convolutional, and Continuous-time Models with the Linear State Space Layer(HiPPO 矩阵的推导)
HiPPO: Recurrent Memory with Optimal Polynomial Projections
How to Train Your HiPPO: State Spaces with Generalized Orthogonal Basis Projections(将 HiPPO矩阵对角化及近似分解)
On the Parameterization and Initialization of Diagonal State Space Models(用在音频处理领域,也有在 Unbounded Music Generation 的应用)
It’s Raw! Audio Generation with State-Space Models上述所有论文开源实现:https://github.com/HazyResearch/state-spaces
SSM 弹簧-阻尼系统:https://zhuanlan.zhihu.com/p/466790657
论文作者视频讲解 S4: https://www.youtube.com/watch?v=luCBXCErkCs
STRUCTURED STATE SPACE DECODER FOR SPEECH RECOGNITION AND SYNTHESIS
最近提出了结构化状态空间模型(S4),为各种长序列建模任务(包括原始语音分类)提供了有希望的结果。S4 模型可以并行训练,与转换器模型相同。在这项研究中,我们将 S4 与 Transformer 解码器进行比较,将其用作 ASR 和文本转语音 (TTS) 任务的解码器。对于ASR任务,我们的实验结果表明,所提出的模型在LibriSpeech测试清洁/测试其他集上实现了1.88%/4.25%的竞争性单词错误率(WER),在CSJ eval1/eval2/eval3集上实现了3.80%/2.63%/2.98%的字符错误率(CER)。此外,所提出的模型比标准变压器模型更健壮,特别是对于两个数据集上的长格式语音。对于TTS任务,所提出的方法优于转换器基线。
(未完待续……)